

Vibe Coding Deployment: Building More Apps, But How to Host?
Vibe coding makes building software extremely fast: requirements are expressed in natural language, an AI produces working code in a short time, and a few iterations later you have MVPs, internal tools, or new features. But this acceleration usually doesn't shift the bottleneck "left" toward development, it shifts it toward operations. While generating code gets cheaper, deployment, maintenance, and security and compliance questions remain the part that costs time, creates risk, and generates organizational friction.
As soon as a handful of services turn into dozens of small applications, like landing pages, APIs, workers, automations, internal dashboards, or self-hosted open-source tools, complexity rarely grows linearly. Every additional deployment expands the attack surface, configuration variants, dependencies, and operational tasks. So the central question becomes: how do you turn "prompt → prod" into a repeatable process that stays stable even at 20, 50, or 200 deployments?
What vibe coding changes
Vibe coding reduces the effort of writing code and increases iteration speed. At the same time, the requirements for professional operations stay fundamentally the same. Responsibilities must be clear, builds must remain reproducible, security standards must not erode, data handling must work reliably, and dealing with outages and rollbacks needs fixed procedures.
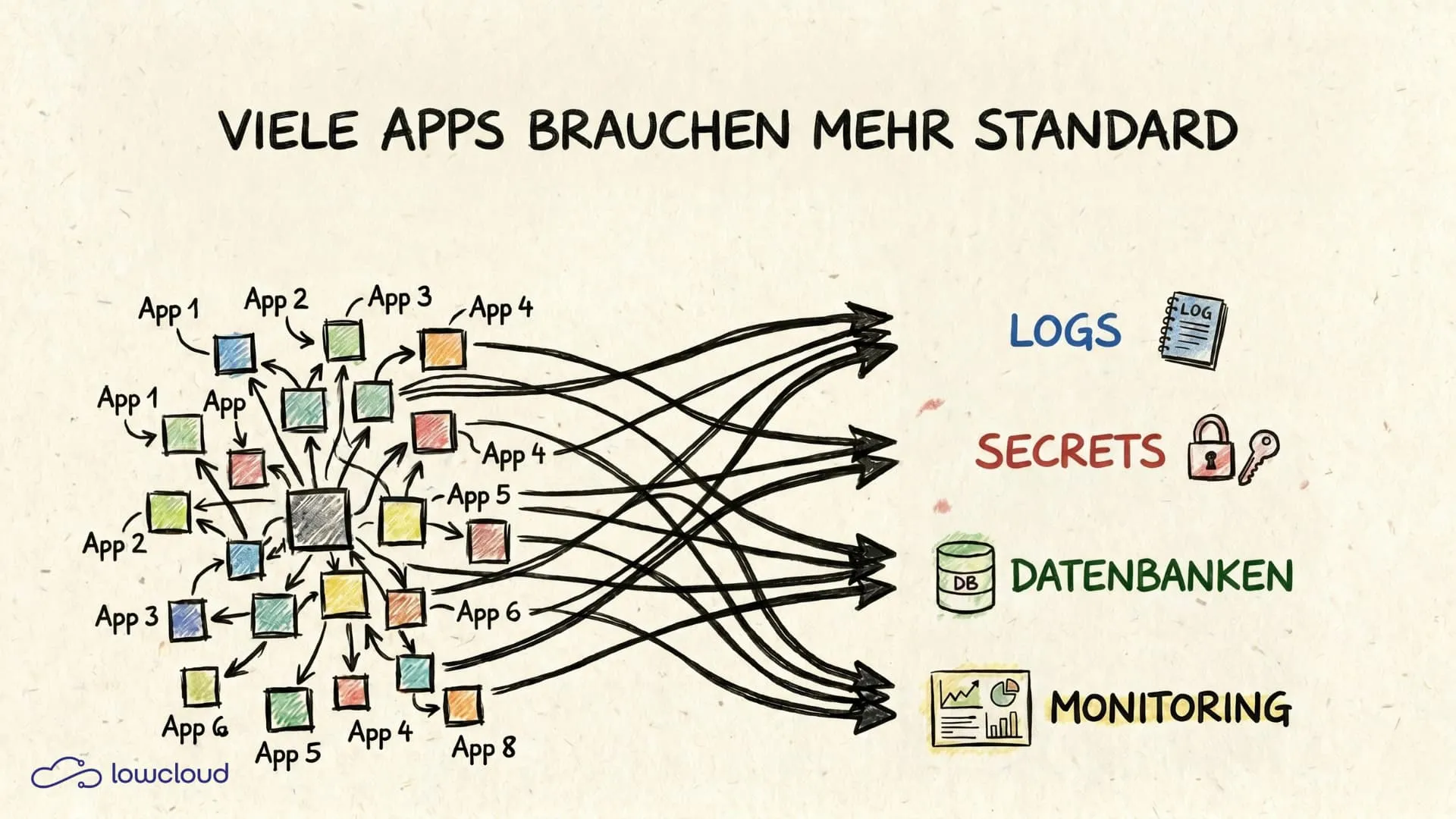
In practice, a growing number of small applications often means not just more features, but above all more operational interfaces: more secrets, more domains, more integrations, more logs, more databases, and more updates. Vibe coding thus increases your production rate without automatically standardizing the infrastructure and process layer that makes operations scalable in the first place.
The real problem: deployment scales organizationally
With "many apps," a setup rarely fails because the tools are unknown. It fails because no standards exist that can be consistently reused. Every new application brings recurring tasks: routing and TLS, environment configuration, secret management, logging, error diagnosis, resource limits, updates, and the question of what to do first during an incident.
So the goal is less "the perfect setup" and more a setup where a new app doesn't trigger a new project. Ideally, introducing another application boils down to a standardized flow: build the image, store the configuration, trigger the deployment, and observability plus backups are ready from the start.
A minimum standard for many applications
Scalable operations start with a few baseline decisions. A clear separation of environments is especially important. Without clean boundaries between development, staging, and production, you quickly get mix-ups, uncontrolled deployments, and unnecessary production risks. Separation typically covers separate secrets, separate databases (or at least separate schemas), and separate deployments with clear promotion logic.
Just as central is secret management without copy-paste. When secrets are managed as local .env files or as manually maintained server variables, you eventually get leaks, missing auditability, and high error-proneness. Professional requirements are secrets per application and environment, least-privilege access, the ability to rotate, and traceable changes.
Logging and error diagnosis also shouldn't be introduced only once problems appear. As long as few services exist, a manual "docker logs" can still work. With many deployments it becomes impractical. Centralized logs, consistent log formats, and error tracking make sense so causes don't have to be hunted in the log noise. On top of that you need a rollback strategy: deployments should be clearly versioned (e.g. via image tags or Git SHAs), and a previous release must be reactivatable in a reproducible way. Database migrations in particular need a plan, otherwise rollbacks fail against already-changed schemas.
Finally, resources and limits must be firmly defined. AI-generated code is often functional, but not necessarily resource-efficient. So CPU and memory limits, health checks, timeouts, and concurrency limits are basic equipment, so individual deployments don't destabilize the entire operation.
Architecture patterns that work in practice
As the number of apps grows, people often reflexively reach for microservices. In many cases a sober assessment is more helpful: a monolith can be very maintainable as long as the domain holds together and there are no hard scaling limits. Many small apps make sense when use cases are clearly separated or when different security and compliance requirements apply. Vibe coding can tempt you to create every feature as its own standalone app. That only holds up when your operational standard actually absorbs the "app growth"; otherwise deliberate consolidation is often more efficient.
Your repo strategy also shapes standardization. A mono-repo makes uniform tooling and policies easier but requires more coordination. Multi-repo setups offer independence but need strong templates and CI standards so that not every app becomes "its own world." In both cases, preview environments are a big lever: if an environment is provisioned automatically for branches or pull requests, you get fewer direct prod risks and feedback can happen earlier.
Container-first: the smallest common denominator
Regardless of whether you use Next.js, FastAPI, Go, or worker workloads: containers are the smallest common denominator for packaging and deploying heterogeneous applications uniformly. Containers improve reproducibility, create standardized interfaces (port in, logs out, configuration via env), and increase portability between hosts and providers. At the same time it's important that containers are only the package format. Secret management, domains, observability, and persistence are solved only by the platform or infrastructure layer that runs the containers.
For many teams it helps to define a "minimal clean" Dockerfile as a standard in templates, so builds stay deterministic and runtime images don't get unnecessarily large or insecure. What matters in particular are pinned dependency states (lockfiles), clear build and runtime stages, and consistent startup behavior.
Setting up CI/CD and GitOps pragmatically
A workable pipeline standard is often more effective than a perfect but heavyweight platform program. The build should follow deterministic rules: lockfiles are mandatory, images get tags by Git SHA instead of "latest," and both dependencies and images are scanned. For deployment, a clear "push as interface" idea helps: changes are rolled out to staging via merge events or releases and then brought to production with defined promotion logic.
GitOps is especially useful when many apps have to follow the same policy framework. Changes to the desired configuration are reviewable, rollbacks become traceable, and configuration drift is reduced. However, GitOps is itself an additional system that has to be operated. For smaller teams, a platform with built-in standards can be the more pragmatic choice when the focus is on speed and operational safety.
Solving stateful right: databases, backups, migrations
Whether a setup works professionally is often decided at "stateful." Stateless apps are comparatively simple. Persistent systems like databases require clear answers: where do the volumes live? How are backups created and how often? Where are backups written? How is restore tested? How are updates done? Who has which access rights?
Backups are only reliable when restore is practiced as a process. A backup that has never been replayed is not a dependable safety mechanism. Migrations must also be plannable. Especially in fast-iterating vibe coding environments, schema changes happen frequently. Best practices are migrations as part of the release, backward-compatible transitions, and where needed feature flags. Without this discipline, every rollback becomes risky, because app version and database schema can drift apart.
Observability: visibility becomes a prerequisite
As the number of deployments grows, "just glancing at the logs" becomes an inadequate approach. A baseline of metrics, centralized logs, (optional) tracing, and actionable alerting is necessary. The RED model works well as a pragmatic standard: request rate, error rate, and duration. Anyone who reliably sees these three values per service can prioritize problems without getting lost in detail.
Standardized logging is an underrated lever here: if logs are structured (e.g. JSON) and enriched with consistent fields, you can correlate across request IDs, services, and deployments. That noticeably reduces diagnosis time, especially with many small applications.
Security and compliance in the vibe coding era
Vibe coding increases productivity, but it also increases the likelihood that insecure defaults end up in production: debug endpoints stay active, CORS or auth configurations are faulty, rate limits are missing, and secrets leak into logs or the repository. That's why supply-chain and dependency hygiene are not optional. Dependency scanning, SBOMs (if compliance is relevant), secure base images, and clean build pipelines reduce risks considerably.
Access models must also be cleanly separated. Deploy rights should not automatically imply database admin rights. Prod secrets belong to a small group of people, and rotation must be possible, for example after team changes or potential leaks. On top of that, the question of data residency becomes more important in many organizations as soon as internal tools process personal data or audits are coming up.
How to choose the hosting stack for many apps
In practice you can distinguish three paths. A VPS setup with Docker Compose is fast and cheap, but scales poorly organizationally once routing, TLS, updates, and multiple environments have to be operated reliably. Kubernetes offers maximum flexibility and policy control, but brings significant complexity and operational overhead. A PaaS or deployment platform can deliver standards as a product: repeatable deployments, consistent defaults, and less manual work per additional application.
| Path | Strengths | Weaknesses | Fits when |
|---|---|---|---|
| VPS + Docker Compose | fast, cheap, full control | scales poorly organizationally, lots of manual work | few apps, one team, early stage |
| Kubernetes | maximum flexibility and policy control | high complexity, its own operational overhead | large team with platform expertise |
| PaaS / deployment platform | standards as a product, consistent defaults | less low-level control | many small apps, focus on speed |
Which option makes sense depends on team size, platform expertise, and your requirements. When vibe coding significantly increases the number of small applications, a platform solution often becomes attractive because it addresses the bottleneck directly: standardize operations without every app triggering a new ops project.
How lowcloud helps
lowcloud positions itself as a sovereign, Germany-hosted alternative for deploying full-stack applications. In an environment with many container-based deployments, the value lies above all in standardizing recurring operational tasks. That typically includes a uniform deployment workflow, consistent routing/TLS, and support for persistent components when applications need databases or other stateful services.
As a result, the operational effort per additional application can drop, because not every deployment demands fresh infrastructure decisions, manual wiring, and individual operational routines. What stays decisive is that standards, roles, and processes are clearly defined, but the platform can provide these standards as a default and thus make scaling operations easier.
A practical roadmap: from "prompt → prod" to "standard → prod"
A pragmatic path to more stability starts with a uniform package format: every application gets a Dockerfile and health checks. Next comes a template approach that ships logging, configuration, and basic security defaults along with it. After that you establish a pipeline that builds images deterministically, tags versions clearly, and brings deployments to staging and production via defined promotion steps.
In parallel, you should standardize stateful out of the apps: databases and backups are treated as fixed operational building blocks, restore processes are tested regularly, and migrations are run as a controlled part of releases. Observability becomes mandatory, not a luxury, so the growing number of deployments doesn't lead to flying blind. Once this baseline is in place, "more apps" turns less automatically into "more stress."
Frequently asked questions
When is a deployment platform worth it over a VPS?
As soon as you have multiple environments, regular routing/TLS, and recurring updates per app. A single VPS with Docker Compose carries a handful of services well. Once those turn into dozens of small apps, the manual effort grows faster than the app count, and a platform with built-in standards pays off.
Do I need Kubernetes for many small apps?
Usually not. Kubernetes offers maximum flexibility but brings its own operational overhead. For many small apps without a dedicated platform team, a PaaS or deployment platform is more pragmatic, because it delivers standards as a product rather than as another system you have to operate yourself.
What's the most important first step toward standardization?
A uniform package format. When every app gets a clean Dockerfile with health checks, you create a common denominator on which pipeline, configuration, logging, and security defaults can build. Without this foundation, every app stays its own special case.
Why are backups worthless without a tested restore?
Because a backup that has never been replayed is not a dependable safety mechanism. Only a practiced restore process shows whether the data is complete, consistent, and quickly recoverable when it counts. So plan restore tests as a fixed part of operations.
Conclusion: more output needs more standard
Vibe coding accelerates development. To keep it from ending in deployment chaos, operations have to be standardized just as much as the code. Containers are a good common denominator, but they're only the means of transport. What's decisive are clean defaults and processes: secret management, logging, backups, rollbacks, clear environments, and dependable observability. The more deployments you create, the stronger this standardization acts as a multiplier.
When vibe coding produces significantly more applications, a setup that consistently standardizes deployment and operations is worth it. Get your apps live in minutes: talk to us about your project.
Server, Docker, SSL: app hosting terms explained
Server, Docker, SSL, backups, environment variables: the key app hosting terms in plain English, and which ones you actually need to know yourself.
Low-Code Backend: Ship Faster, Skip the Ops
Low-code backend takes repetitive work off developers: ship faster, less boilerplate. The categories, the limits, and what makes a good platform.