

Vibe Coding Deployment: viele Apps bauen, aber wie hosten?
Vibe Coding macht das Erstellen von Software extrem schnell: Anforderungen werden in natürlicher Sprache formuliert, eine KI erzeugt in kurzer Zeit lauffähigen Code, und mit einigen Iterationen entstehen MVPs, interne Tools oder neue Features. Diese Beschleunigung verschiebt den Engpass jedoch meist nicht „nach links" in Richtung Entwicklung, sondern in Richtung Betrieb. Während Code-Erzeugung günstiger wird, bleiben Deployment, Wartung und Sicherheits- und Compliance-Fragen der Teil, der Zeit, Risiko und organisatorische Reibung verursacht.
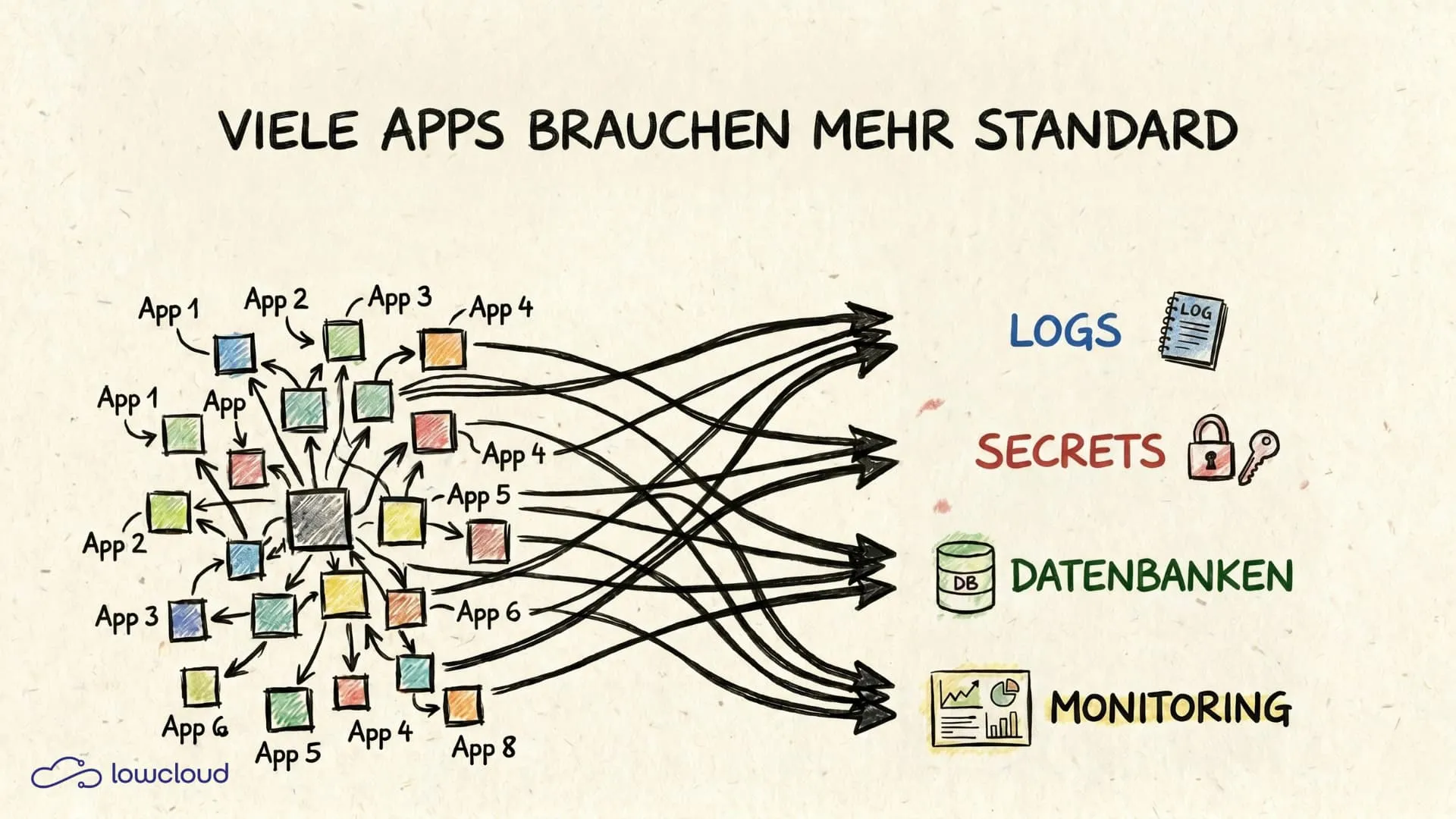
Sobald aus wenigen Services Dutzende kleine Anwendungen werden, wie Landingpages, APIs, Worker, Automatisierungen, interne Dashboards oder Self-hosted Open-Source-Tools, steigt die Komplexität selten linear. Mit jedem zusätzlichen Deployment wachsen Angriffsfläche, Konfigurationsvarianten, Abhängigkeiten und Betriebsaufgaben. Die zentrale Frage lautet daher: Wie lässt sich „Prompt → Prod" in einen wiederholbaren Prozess überführen, der auch mit 20, 50 oder 200 Deployments stabil bleibt?
Was Vibe Coding verändert
Vibe Coding reduziert den Aufwand für das Schreiben von Code und erhöht die Geschwindigkeit der Iteration. Gleichzeitig bleiben die Anforderungen an einen professionellen Betrieb grundsätzlich gleich. Verantwortlichkeiten müssen geklärt sein, Builds müssen reproduzierbar bleiben, Sicherheitsstandards dürfen nicht erodieren, Datenhaltung muss verlässlich funktionieren, und der Umgang mit Ausfällen sowie Rollbacks braucht feste Abläufe.
In der Praxis zeigt sich häufig, dass eine steigende Zahl kleiner Anwendungen nicht nur mehr Features bedeutet, sondern vor allem mehr operative Schnittstellen: mehr Secrets, mehr Domains, mehr Integrationen, mehr Logs, mehr Datenbanken und mehr Updates. Vibe Coding erhöht somit die Produktionsrate, ohne automatisch die Infrastruktur- und Prozessschicht zu standardisieren, die den Betrieb überhaupt erst skalierbar macht.
Das eigentliche Problem: Deployment skaliert organisatorisch
Bei „vielen Apps" scheitert ein Setup selten daran, dass keine Tools bekannt sind. Es scheitert daran, dass keine Standards existieren, die sich konsequent wiederverwenden lassen. Jede neue Anwendung bringt wiederkehrende Aufgaben mit sich: Routing und TLS, Environment-Konfiguration, Secret-Verwaltung, Logging, Fehlerdiagnose, Ressourcenlimits, Updates und die Frage, was im Incident-Fall zuerst getan wird.
Das Ziel ist daher weniger „das perfekte Setup", sondern ein Setup, in dem eine neue App kein neues Projekt auslöst. Idealerweise reduziert sich die Einführung einer weiteren Anwendung auf einen standardisierten Ablauf: Build erzeugen, Konfiguration hinterlegen, Deployment auslösen, und Observability sowie Backups stehen von Beginn an bereit.
Mindeststandard für viele Anwendungen
Ein skalierbarer Betrieb beginnt mit einigen Baseline-Entscheidungen. Besonders wichtig ist eine klare Trennung von Umgebungen. Ohne saubere Abgrenzung von Development, Staging und Production entstehen schnell Verwechslungen, unkontrollierte Deployments und unnötige Produktionsrisiken. Eine Trennung umfasst typischerweise getrennte Secrets, getrennte Datenbanken (oder mindestens getrennte Schemas) sowie getrennte Deployments mit klarer Promotion-Logik.
Ebenso zentral ist Secret-Management ohne Copy-Paste. Werden Secrets als lokale .env-Dateien oder als manuell gepflegte Servervariablen verwaltet, entstehen auf Dauer Leaks, fehlende Auditierbarkeit und eine hohe Fehleranfälligkeit. Professionelle Anforderungen sind Secrets pro Anwendung und Umgebung, Least-Privilege-Zugriffe, Rotationsfähigkeit und nachvollziehbare Änderungen.
Auch Logging und Fehlerdiagnose sollten nicht erst dann eingeführt werden, wenn Probleme auftreten. Solange wenige Services existieren, kann ein manuelles „docker logs" noch funktionieren. Bei vielen Deployments wird das unpraktikabel. Sinnvoll sind zentrale Logs, konsistente Logformate sowie Fehlertracking, damit Ursachen nicht im Lograuschen gesucht werden müssen. Ergänzend braucht es eine Rollback-Strategie: Deployments sollten eindeutig versioniert sein (z. B. über Image-Tags oder Git-SHAs), und ein vorheriger Release muss reproduzierbar reaktivierbar sein. Besonders bei Datenbankmigrationen ist ein Plan erforderlich, weil Rollbacks sonst an bereits veränderten Schemas scheitern.
Schließlich müssen Ressourcen und Limits fest definiert sein. KI-generierter Code ist oft funktional, aber nicht zwingend ressourcenschonend. Daher sind CPU-/Memory-Limits, Health Checks, Timeouts und Concurrency-Limits eine Grundausstattung, damit einzelne Deployments nicht den gesamten Betrieb destabilisieren.
Architektur-Patterns, die in der Praxis funktionieren
Mit steigender App-Anzahl wird häufig reflexartig über Microservices nachgedacht. In vielen Fällen ist eine nüchterne Einordnung hilfreicher: Ein Monolith kann sehr wartbar sein, solange die Domäne zusammenhängt und keine harten Skalierungsgrenzen bestehen. Viele kleine Apps sind sinnvoll, wenn Anwendungsfälle klar getrennt sind oder unterschiedliche Sicherheits- und Compliance-Anforderungen vorliegen. Vibe Coding kann dazu verleiten, jedes Feature als eigenständige App zu erzeugen. Das ist nur dann tragfähig, wenn der Betriebsstandard den „App-Zuwachs" wirklich abfedert; andernfalls ist bewusste Konsolidierung oft effizienter.
Auch die Repo-Strategie beeinflusst die Standardisierung. Ein Mono-Repo erleichtert einheitliches Tooling und Policies, erfordert jedoch mehr Koordination. Multi-Repo-Setups bieten Unabhängigkeit, brauchen aber starke Templates und CI-Standards, damit nicht jede App „ihre eigene Welt" wird. In beiden Fällen sind Preview Environments ein großer Hebel: Wird für Branches oder Pull Requests automatisch eine Umgebung bereitgestellt, entstehen weniger direkte Prod-Risiken, und Feedback kann früher stattfinden.
Container-first: der kleinste gemeinsame Nenner
Unabhängig davon, ob Next.js, FastAPI, Go oder Worker-Workloads eingesetzt werden: Container sind der kleinste gemeinsame Nenner, um heterogene Anwendungen einheitlich zu paketieren und zu deployen. Container verbessern Reproduzierbarkeit, schaffen standardisierte Schnittstellen (Port rein, Logs raus, Konfiguration per Env) und erhöhen die Portabilität zwischen Hosts und Providern. Gleichzeitig ist wichtig, dass Container nur das Paketformat darstellen. Secret-Management, Domains, Observability und Persistenz werden erst durch die Plattform- oder Infrastruktur-Schicht gelöst, die Container ausführt.
Für viele Teams ist es hilfreich, ein „minimal sauberes" Dockerfile als Standard in Templates zu definieren, damit Builds deterministisch bleiben und Laufzeitimages nicht unnötig groß oder unsicher sind. Entscheidend sind dabei insbesondere feste Abhängigkeitsstände (Lockfiles), klare Build- und Runtime-Stages und ein konsistentes Startverhalten.
CI/CD und GitOps pragmatisch aufsetzen
Ein praktikabler Pipeline-Standard ist oft wirkungsvoller als ein perfektes, aber schwergewichtiges Plattformprogramm. Für den Build sollten deterministische Regeln gelten: Lockfiles sind verpflichtend, Images erhalten Tags nach Git-SHA statt „latest", und sowohl Dependencies als auch Images werden gescannt. Für das Deployment ist ein klarer „Push als Interface"-Gedanke hilfreich: Änderungen werden über Merge-Events oder Releases in Staging ausgerollt und anschließend mit definierter Promotion-Logik nach Production gebracht.
GitOps ist besonders dann sinnvoll, wenn viele Apps denselben Policy-Rahmen einhalten müssen. Änderungen an der gewünschten Konfiguration sind reviewbar, Rollbacks werden nachvollziehbar, und Konfigurationsdrift wird reduziert. Allerdings ist GitOps selbst ein zusätzliches System, das betrieben werden muss. Für kleinere Teams kann eine Plattform mit eingebauten Standards die pragmatischere Wahl sein, wenn der Fokus auf Geschwindigkeit und Betriebssicherheit liegt.
Stateful richtig lösen: Datenbanken, Backups, Migrationen
Ob ein Setup professionell funktioniert, entscheidet sich oft bei „Stateful". Stateless Apps sind vergleichsweise einfach. Persistente Systeme wie Datenbanken erfordern klare Antworten: Wo liegen Volumes? Wie werden Backups erstellt und wie oft? Wohin werden Backups geschrieben? Wie wird Restore getestet? Wie erfolgen Updates? Wer hat welche Zugriffsrechte?
Backups sind nur dann verlässlich, wenn Restore als Prozess geübt wird. Ein Backup, das nie zurückgespielt wurde, ist kein belastbarer Sicherheitsmechanismus. Ebenso müssen Migrationen planbar sein. Gerade in schnell iterierenden Vibe-Coding-Umgebungen treten Schemaänderungen häufig auf. Best Practices sind Migrationen als Teil des Releases, rückwärtskompatible Übergänge, und wo nötig Feature Flags. Ohne diese Disziplin wird jeder Rollback riskant, weil App-Version und Datenbankschema auseinanderlaufen können.
Observability: Sichtbarkeit wird zur Grundvoraussetzung
Mit steigender Anzahl von Deployments wird „mal in die Logs schauen" zum unzureichenden Ansatz. Eine Baseline aus Metrics, zentralisierten Logs, (optional) Tracing und einem handlungsfähigen Alerting ist notwendig. Als pragmatischer Standard eignet sich das RED-Modell: Request Rate, Error Rate und Duration. Wer diese drei Werte pro Service zuverlässig sieht, kann Probleme priorisieren, ohne sich im Detail zu verlieren.
Standardisiertes Logging ist dabei ein unterschätzter Hebel: Werden Logs strukturiert (z. B. JSON) und um konsistente Felder ergänzt, können Korrelationen über Request-IDs, Services und Deployments hinweg hergestellt werden. Das reduziert Diagnosezeit deutlich, besonders bei vielen kleinen Anwendungen.
Security & Compliance im Vibe-Coding-Zeitalter
Vibe Coding erhöht Produktivität, erhöht aber auch die Wahrscheinlichkeit, dass unsichere Defaults in Produktion landen: Debug-Endpunkte bleiben aktiv, CORS- oder Auth-Konfigurationen sind fehlerhaft, Rate Limits fehlen, und Secrets geraten in Logs oder ins Repository. Deshalb sind Supply-Chain- und Dependency-Hygiene nicht optional. Dependency-Scanning, SBOMs (falls Compliance relevant ist), sichere Base-Images und saubere Build-Pipelines reduzieren Risiken erheblich.
Auch Zugriffsmodelle müssen sauber getrennt sein. Deploy-Rechte sollten nicht automatisch Datenbank-Admin-Rechte implizieren. Prod-Secrets gehören auf einen kleinen Personenkreis begrenzt, und Rotationen müssen möglich sein, etwa bei Teamwechseln oder potenziellen Leaks. Zusätzlich wird in vielen Organisationen die Frage der Datenresidenz wichtiger, sobald interne Tools personenbezogene Daten verarbeiten oder Audits anstehen.
Wie der Hosting-Stack für viele Apps ausgewählt wird
In der Praxis lassen sich drei Wege unterscheiden. Ein VPS-Setup mit Docker Compose ist schnell und günstig, skaliert jedoch organisatorisch schlecht, sobald Routing, TLS, Updates und mehrere Umgebungen zuverlässig betrieben werden sollen. Kubernetes bietet maximale Flexibilität und Policy-Steuerung, bringt aber signifikante Komplexität und Betriebsaufwand mit sich. Eine PaaS- oder Deployment-Plattform kann Standards als Produkt liefern: wiederholbare Deployments, konsistente Defaults, und weniger Handarbeit pro zusätzlicher Anwendung.
| Weg | Stärken | Schwächen | Passt, wenn |
|---|---|---|---|
| VPS + Docker Compose | schnell, günstig, volle Kontrolle | skaliert organisatorisch schlecht, viel Handarbeit | wenige Apps, ein Team, frühe Phase |
| Kubernetes | maximale Flexibilität und Policy-Steuerung | hohe Komplexität, eigener Betriebsaufwand | großes Team mit Plattformkompetenz |
| PaaS / Deployment-Plattform | Standards als Produkt, konsistente Defaults | weniger Tiefenkontrolle | viele kleine Apps, Fokus auf Tempo |
Welche Option sinnvoll ist, hängt von Teamgröße, Plattformkompetenz und den Anforderungen ab. Wenn Vibe Coding die Zahl kleiner Anwendungen deutlich erhöht, wird eine Plattformlösung oft attraktiv, weil sie den Engpass direkt adressiert: Betrieb standardisieren, ohne dass jede App ein neues Ops-Projekt auslöst.
Wie lowcloud hilft
lowcloud positioniert sich als souveräne, in Deutschland gehostete Alternative für das Deployment von Full-Stack-Anwendungen. In einem Umfeld mit vielen Container-basierten Deployments liegt der Nutzen vor allem darin, wiederkehrende Betriebsaufgaben zu standardisieren. Dazu gehören typischerweise ein einheitlicher Deployment-Workflow, konsistentes Routing/TLS, sowie Unterstützung für persistente Komponenten, wenn Anwendungen Datenbanken oder andere Stateful-Dienste benötigen.
Im Ergebnis kann der operative Aufwand pro zusätzlicher Anwendung sinken, weil nicht jedes Deployment erneut Infrastruktur-Entscheidungen, manuelle Verkabelung und individuelle Betriebsroutinen verlangt. Entscheidend bleibt dabei, dass Standards, Rollen und Prozesse klar definiert sind, die Plattform kann diese Standards jedoch als Default bereitstellen und so die Skalierung des Betriebs erleichtern.
Ein praktischer Fahrplan: von „Prompt → Prod" zu „Standard → Prod"
Ein pragmatischer Weg zu mehr Stabilität beginnt mit einem einheitlichen Paketformat: Jede Anwendung erhält ein Dockerfile und Health Checks. Darauf folgt ein Template-Ansatz, der Logging, Konfiguration und grundlegende Security-Defaults mitliefert. Anschließend wird eine Pipeline etabliert, die Images deterministisch baut, Versionen eindeutig taggt und Deployments über definierte Promotion-Schritte in Staging und Production bringt.
Parallel sollte Stateful aus den Apps heraus standardisiert werden: Datenbanken und Backups werden als feste Betriebsbausteine behandelt, Restore-Prozesse werden regelmäßig getestet, und Migrationen werden als kontrollierter Teil von Releases geführt. Observability wird zur Pflicht, nicht zum Luxus, damit die wachsende Zahl an Deployments nicht zu Blindflug führt. Sobald diese Baseline steht, wird „mehr Apps" weniger automatisch zu „mehr Stress".
Häufige Fragen
Ab wann lohnt sich eine Deployment-Plattform statt eines VPS?
Sobald mehrere Umgebungen, regelmäßiges Routing/TLS und wiederkehrende Updates pro App anfallen. Ein einzelner VPS mit Docker Compose trägt eine Handvoll Services gut. Sobald daraus Dutzende kleine Apps werden, steigt der manuelle Aufwand schneller als die App-Zahl, und eine Plattform mit eingebauten Standards rechnet sich.
Brauche ich Kubernetes für viele kleine Apps?
Meistens nicht. Kubernetes bietet maximale Flexibilität, bringt aber eigenen Betriebsaufwand mit. Für viele kleine Apps ohne dediziertes Plattform-Team ist eine PaaS oder Deployment-Plattform pragmatischer, weil sie Standards als Produkt liefert statt als zusätzliches System, das selbst betrieben werden muss.
Was ist der wichtigste erste Schritt zur Standardisierung?
Ein einheitliches Paketformat. Wenn jede App ein sauberes Dockerfile mit Health Checks bekommt, entsteht ein gemeinsamer Nenner, auf dem Pipeline, Konfiguration, Logging und Security-Defaults aufsetzen können. Ohne dieses Fundament bleibt jede App ihre eigene Sonderlösung.
Warum sind Backups ohne getesteten Restore wertlos?
Weil ein Backup, das nie zurückgespielt wurde, kein belastbarer Sicherheitsmechanismus ist. Erst der geübte Restore-Prozess zeigt, ob die Daten vollständig, konsistent und im Ernstfall schnell wiederherstellbar sind. Plane Restore-Tests deshalb als festen Bestandteil des Betriebs ein.
Fazit: mehr Output braucht mehr Standard
Vibe Coding beschleunigt Entwicklung. Damit dies nicht im Deployment-Chaos endet, muss der Betrieb genauso standardisiert werden wie der Code. Container sind ein guter gemeinsamer Nenner, aber sie sind nur das Transportmittel. Entscheidend sind saubere Defaults und Prozesse: Secret-Management, Logging, Backups, Rollbacks, klare Umgebungen und belastbare Observability. Je mehr Deployments entstehen, desto stärker wirkt diese Standardisierung als Multiplikator.
Wenn durch Vibe Coding deutlich mehr Anwendungen entstehen, lohnt sich ein Setup, das Deployment und Betrieb konsequent standardisiert. Bring deine Apps in wenigen Minuten live: sprich mit uns über dein Projekt.
Server, Docker, SSL: was du fürs App-Hosting brauchst
Server, Docker, SSL, Backups, Environment Variables: wir erklären die wichtigsten App-Hosting-Begriffe in Klartext, und welche du davon selbst können musst.
Low-Code Backend: Schneller deployen, weniger Ops
Low-Code Backend nimmt Entwicklern repetitive Arbeit ab: schneller deployen, weniger Boilerplate. Kategorien, Grenzen und worauf es bei der Plattform ankommt.