

Citizen Developers: Easy to Code, Hard to Deploy
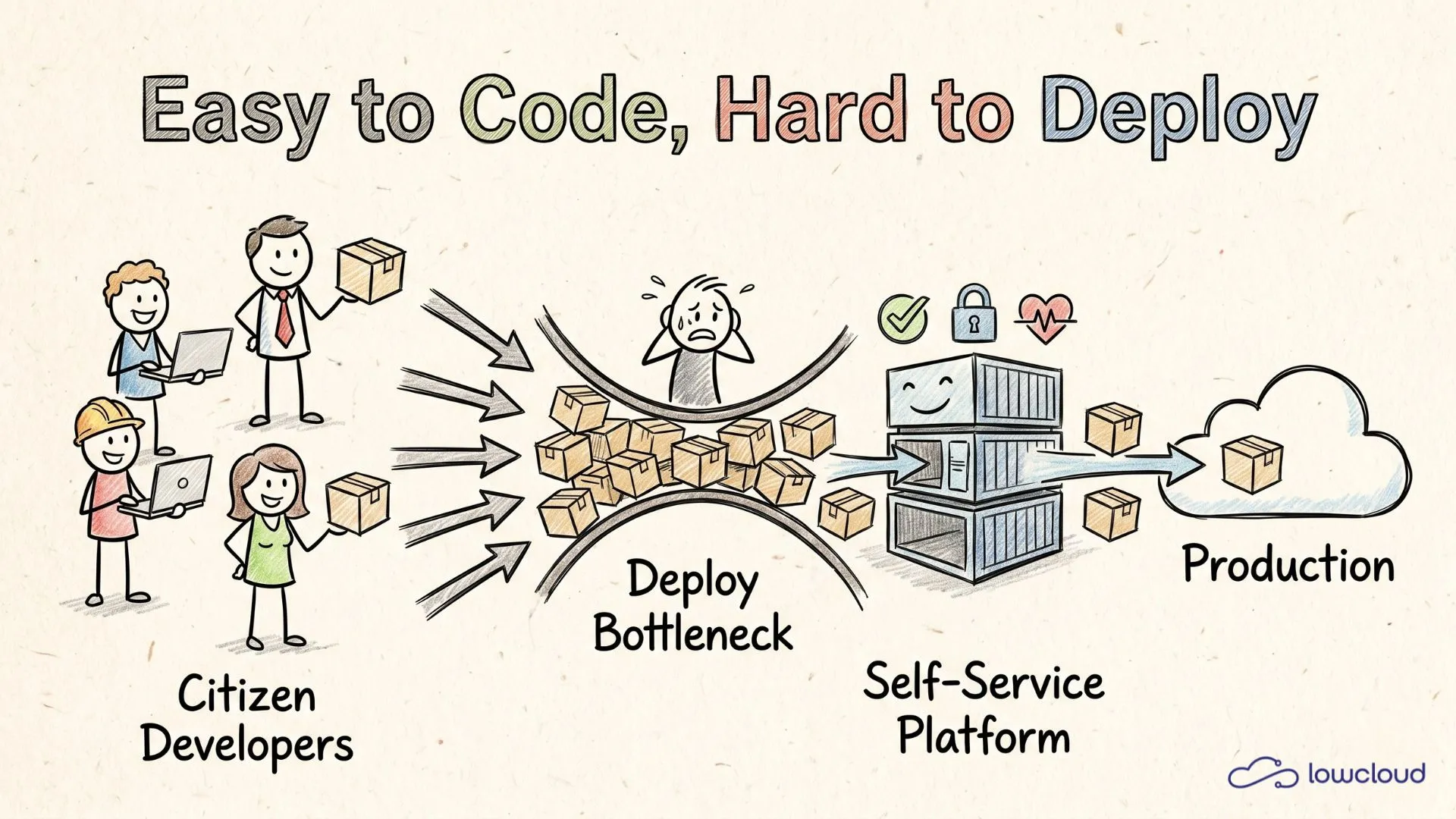
Vibe coding lowers the barrier to programming so much that suddenly far more people in a company can "build software" — at least up to the point where the code runs locally. That's exactly where reality flips: the moment a prototype turns into a service that has to run reliably, be monitored, updated, and secured, deployment and operations become the bottleneck.
This article explains why that happens, what risks come with it, and how you can use platform engineering and self-service deployment to keep citizen developers and product teams productive without shadow IT and compliance blowing up in your face.
What "vibe coding" actually changes (and what it doesn't)
The term vibe coding doesn't describe "magical programming without thinking." It describes a new way of working: people state a goal, let LLMs suggest code, iterate quickly, and accept that not every line has to be understood in detail as long as the result is right. For certain classes of problems, this works surprisingly well:
- small internal tools
- UI-heavy prototypes
- scripts and automations
- glue code between APIs
- data preparation and reporting
What it doesn't automatically solve: architecture decisions, security concepts, lifecycle management, releases, data handling, observability. But those are exactly the topics that become relevant from day 2 onward (Day 2 operations).
The most important mental shift: vibe coding makes "building a solution" easier. It does not make "operating a solution responsibly" easier — quite the opposite, because more solutions get created.
Why suddenly more teams are shipping software
When the effort to get from "I have an idea" to "I have something that works" drops drastically, behavior inside organizations changes. Instead of handing tickets to engineering and waiting weeks, business units build things themselves:
- Sales builds a tool that merges leads from several sources.
- Finance automates reports and approval processes.
- Operations puts together a dashboard for supply chain status.
- Marketing uses webhooks to sync campaign events.
- Data teams build small services that enrich or validate data.
None of this is new (Excel macros, Access databases, Zapier, and low-code have always existed). What's new is how quickly it turns into "real software": web UIs, small APIs, cron jobs, containers that have to run somewhere.
This also shifts the role of engineering: less as "the producer of every single app," more as "operator and enabler" — in other words, platform engineering.
The new bottleneck: deployment & operations
The note snippet on the page already captures the core: "the bottleneck is shifting toward deployment and operations." That's the typical second phase after the vibe-coding euphoria, and it mirrors what happens when AI codes faster than you can deploy.
Why deployment is harder than "generating code"
An LLM can write you a small backend in minutes, but the typical deployment problems with vibe code show up the moment it leaves your machine. For it to be usable in a company, you need answers to questions like:
- Where does this thing run? (environment, cluster, region)
- How does it get there? (CI/CD, build, deploy)
- How are secrets handled? (API keys, DB passwords)
- What does observability look like? (logs, metrics, alerts)
- Who owns it? (on-call, incidents, budget)
- How do we patch security holes? (base images, dependencies)
- How do we do rollbacks? (versioning, releases)
- How do we handle data? (backups, migrations, GDPR)
If these topics aren't standardized, every new "small service" becomes a one-off. That doesn't scale.
What breaks first in practice
Typical symptoms when many teams start shipping on their own:
- Secrets end up in code or in chat tools.
- "It's only internal" becomes the standard excuse — until it's an incident.
- No monitoring: errors are only discovered when someone screams.
- Unclear ownership: nobody feels responsible when it breaks at night.
- Costs spiral: a VM experiment here, a cloud service there — nobody has the full picture.
- Compliance gaps: data leaves regions, logs contain personal data, access isn't auditable.
This is shadow IT from vibe coding, modernized: no longer just SaaS tools, but self-built deployments.
Risks without a platform: shadow IT, costs, compliance
Citizen developers are not the problem. The problem is when a company has citizen developers but no platform and no clear guardrails.
Shadow IT: the consequence, not the cause
Shadow IT emerges when the "official path" is too slow or too expensive. Vibe coding amplifies that: the code is there fast, so people also look for somewhere "to deploy it" — if need be with private accounts, free PaaS offerings, or copy-paste tutorials from the internet.
The result is a landscape of services that:
- nobody has documented
- nobody patches
- nobody monitors
- nobody shuts down
Compliance and sovereignty become "product-relevant" again
In Germany and Europe especially, this point is not optional: data residency, data processing agreements, audit logs, access control. When more departments code, the likelihood rises that someone accidentally:
- pushes personal data into non-compliant tools
- deploys services into regions that aren't allowed
- doesn't follow deletion and retention rules
That makes sovereignty a practical engineering topic, not just a procurement topic.
Guardrails instead of gatekeeping: how to scale productivity
The productive answer is not "a ban." That doesn't work in reality. The productive answer is: guardrails.
Guardrails are technical and organizational standards that make the default safe. Good guardrails reduce the number of decisions per team and prevent the most common mistakes.
Building blocks that have proven themselves
- Standardized deploy targets: container platform, jobs, cron, and possibly functions — but clearly defined.
- Templates: repo templates for typical app classes (API, worker, frontend + backend, cron job).
- CI/CD as default: a commit should build and deploy reproducibly.
- Approved base images: centrally maintained, regularly patched.
- Secret management: no copy-paste, but defined mechanisms.
- Observability by default: logging, metrics, alerts — ideally automatic.
- Policy-as-code: network rules, quotas, approvals for databases/storage.
- Ownership & lifecycle: Who owns it? How is it deprovisioned? What counts as "abandoned"?
A simple operating model for "many small apps"
You don't need an enterprise monster to get started. A minimal standard is enough if it's applied consistently. For example:
- Every app is a container.
- Every app has a repo with a template structure.
- Every app automatically gets:
- a deployment (staging/prod)
- logs
- basic metrics
- a health check
- rollback via version pin
- Databases are provided as a managed service (including backups).
That turns "I built something" into "I can run it safely."
Platform engineering in one sentence: self-service deployment for teams
At its core, platform engineering is this: engineering builds a platform that lets teams ship services quickly and safely — with clear standards. It's the exact countermovement to "every app is a snowflake deployment."
When vibe coding produces more output, the platform has to raise throughput. Otherwise your central team stands in the way as the bottleneck:
- "Can you deploy this?"
- "Can you set a secret?"
- "Can you add monitoring?"
- "Can you provision a DB?"
The platform should answer these questions with a self-service workflow.
lowcloud as a sovereign deploy and operations foundation
When you notice more departments shipping software, what you need most is one thing: a unified, sovereign foundation for deployment and operations. Many teams sit right in this gap: they can produce the code quickly, but they need a reliable platform to get it into production without huge operational overhead.
lowcloud is interesting here as a PaaS/platform because it directly addresses typical "day 2" topics:
- One-click deployment for container-based services (less manual work, fewer individual setups)
- Container deployment as the standard: the same mechanics for many app classes
- Stateful deployments including databases, when the app isn't just stateless
- Full-stack deployment: frontend + backend operable consistently
- Monitoring/observability as a built-in part, rather than bolted on afterward
- Sovereignty & Germany-based hosting: relevant for compliance, data residency, and auditable operational processes
The important thing: a platform doesn't replace good engineering. But it takes the repetitive parts off your hands and ensures that new services don't start from scratch every time — exactly what you need with a growing number of citizen developer projects.
Shadow IT from Vibe Coding: The New Governance Risk
Vibe coding creates a new kind of shadow IT: self-built apps with no maintenance, no security, no GDPR. Why bans fail and how a platform fixes it.
Server, Docker, SSL: app hosting terms explained
Server, Docker, SSL, backups, environment variables: the key app hosting terms in plain English, and which ones you actually need to know yourself.