

Platform Engineering: Ship Faster Without Ops Tickets
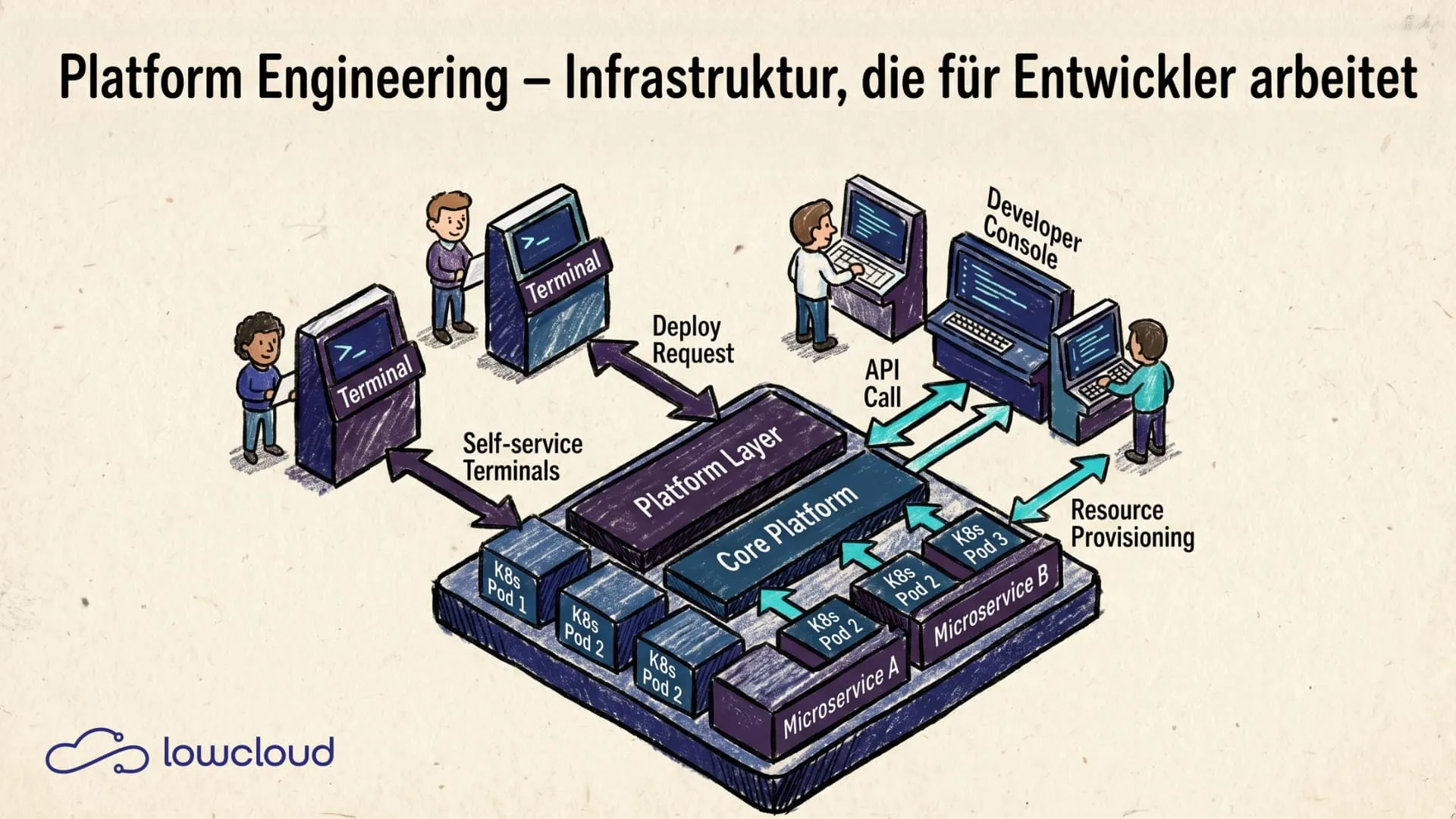
Development teams spend too much time configuring infrastructure instead of building software. Tickets to ops teams, weeks of waiting for environments, inconsistent deployment processes. This isn't an isolated problem, it's everyday reality in many companies. Platform engineering is the approach that systematically removes this overhead: through internal platforms that give developers what they need, without the detour through an ops ticket — and increasingly the lever that pulls vibe-coding shadow IT back under governance. It is also the answer when citizen developers ship more software than ops can deploy.
What is platform engineering?
Platform engineering is the discipline concerned with building and operating internal developer platforms. The goal: development teams should be able to work more productively by being given a well-designed, self-serviceable infrastructure.
The term is closely tied to the concept of the Internal Developer Platform (IDP), a platform layer that abstracts and automates frequently recurring tasks like provisioning environments, configuring CI/CD pipelines, or deploying to Kubernetes.
Platform engineering is neither a new tool nor a framework, but an organizational and technical practice. It's about how teams are set up, what responsibilities they hold, and what tools they use to take the load off developers.
The Internal Developer Platform
The IDP is the heart of platform engineering. It's not off-the-shelf software you can buy, but a system that a platform team builds and operates, tailored to the needs of its own developers.
A well-built IDP offers:
- Self-service infrastructure: Developers can provision environments, databases, or deployments on demand, without having to ask anyone.
- Standardized workflows: Recurring steps like creating a new service or setting up a staging environment are templated and reproducible.
- Abstraction of complexity: Developers don't have to write Kubernetes manifests or understand Terraform modules – the platform handles the details, increasingly with low-code backend tooling on top.
- Unified observability: Logging, monitoring, and alerting are built in from the start.
The concrete setup varies widely from company to company. Some rely on Backstage as a developer portal, others build their platform directly on GitOps tools like ArgoCD. What matters isn't the tooling but the principle: the platform serves the developers, not the other way around.
The Golden Path
A term that keeps coming up in platform engineering discussions is the Golden Path, sometimes also called the Paved Road. It refers to a predefined, recommended way for how a service should be built, deployed, and operated.
The Golden Path isn't mandatory. Developers can deviate from it if they have good reasons. But it makes the right way the easy way. If the template for a new microservice already comes with CI/CD, monitoring, and a sensible Kubernetes configuration, hardly anyone will want to start from scratch.
This significantly reduces cognitive load. New team members become productive faster. Security and compliance requirements can be built into the path once instead of into each service individually. And platform updates can be rolled out centrally, without manually coordinating with every team.
Platform engineering vs. DevOps vs. SRE
The three terms often get muddled. They're related, but not identical.
DevOps is a culture and practice that brings development and operations closer together. It's about breaking down silos and creating shared responsibility for software across its entire lifecycle. DevOps isn't a team, it's a mindset.
Site Reliability Engineering (SRE) is a concrete implementation model that Google developed. SRE teams are responsible for the reliability of production systems. They work with error budgets, SLOs, and SLIs, and step in during incidents.
Platform engineering is the logical evolution of both approaches. While DevOps fostered collaboration and SRE standardized reliability, platform engineering goes one step further: it builds the infrastructure developers need so they can practice DevOps in the first place – without every team reinventing the wheel. For a focused breakdown of platform engineering vs. DevOps, including when an IDP is worth the investment, see our dedicated comparison.
In practice there are overlaps. Platform teams solve reliability problems structurally, before they arise. And DevOps remains the cultural foundation that platform engineering builds on.
Roles and responsibilities of a platform team
A platform team isn't a classic ops team. It sees itself as an internal service provider for development teams – with the difference that it doesn't work through tickets, but builds systems that make tickets unnecessary.
Typical responsibilities:
- Designing and evolving the IDP
- Managing the Kubernetes clusters and associated infrastructure
- Providing tooling for CI/CD, secrets management, networking, and observability
- Developing and maintaining templates and Golden Paths
- Documentation and enablement – the platform team has to be able to explain what it built
The most important trait of a platform team is product thinking. The developers are the customers. If the platform isn't used or is seen as cumbersome, the platform team has a problem – just like a product team whose feature nobody uses.
Tools in the platform engineering stack
There's no single standard stack. The tools are assembled based on requirements. A few common components:
- Backstage: Spotify's developer portal, which can serve as the frontend for the IDP. Offers service catalogs, templates, and documentation in one place.
- Crossplane: Kubernetes-native infrastructure as code. Lets you manage cloud resources as Kubernetes objects.
- ArgoCD / Flux: GitOps tools for Kubernetes deployments. Keep cluster state in sync with a Git repository.
- Terraform / OpenTofu: Classic infrastructure as code for cloud resources outside Kubernetes.
- Vault: Secrets management. Makes sure credentials don't end up in Git.
- Prometheus + Grafana: The standard stack for monitoring and visualization.
The art isn't in combining all the tools, but in making the right selection and integrating them so they're easy for developers to use.
Kubernetes as the foundation
Most modern Internal Developer Platforms rely on Kubernetes as the orchestration layer. There are good reasons for this: Kubernetes offers a declarative API that's well suited for self-service, is cloud-agnostic, and has a broad ecosystem.
At the same time, Kubernetes is complex. The learning curve is steep, and configuring a production-ready cluster is far from trivial. That's exactly where platform engineering comes in: the platform team manages Kubernetes so that development teams can use it without having to fully understand it.
A developer should be able to deploy a service without writing a Kubernetes manifest. The platform translates a simple configuration, in YAML or through a web UI, into the corresponding Kubernetes resources. This is exactly how abstraction layers simplify Kubernetes configuration in practice.
How do you measure success?
Platform engineering without metrics is hard to justify. The most important numbers come from two areas:
DORA Metrics measure the performance of development teams:
- Deployment Frequency: How often do you deploy?
- Lead Time for Changes: How long does it take from commit to production?
- Change Failure Rate: How many deployments lead to incidents?
- Mean Time to Restore: How quickly are incidents resolved?
A well-built platform improves all four values. When deployments become easier and safer, they happen more often and with fewer errors.
Developer Experience (DevEx) is harder to measure, but no less important. A zero-config Kubernetes approach with sensible defaults is one of the clearest levers for improving it. Surveys, onboarding time for new developers, and the adoption rate of platform features all reveal whether the platform really helps or just formally exists.
How do you get started?
The most common mistake when getting into platform engineering is trying to build everything at once. That's the surest way to end up with a system after six months that nobody uses.
A sensible start:
- Identify pain points: Where do developers lose the most time? Which requests go to ops teams most often?
- Start small: Automate a single use case – for example, setting up a new staging environment.
- Gather feedback: The developers you're building for should be involved from the start.
- Iterate: The platform grows with the requirements. No big bang.
If you don't have the time and capacity to build a complete internal platform from scratch, you can also use a ready-made PaaS that already brings along many of the concepts described, such as lowcloud. As a platform, lowcloud delivers a Golden Path for deployments, CI/CD, and infrastructure management, without having to build your own platform team. It's not a replacement for platform engineering as a mindset, but a pragmatic entry point for teams that want to move fast.
Host Your App GDPR-Compliant in the EU: a Checklist
How to host your app legally in the EU: a practical checklist for providers, contracts and tech, in the wake of Schrems II and the CLOUD Act.
Deploy Your Vibe-Coded App: Fast, Cheap, EU-Hosted
Push-to-deploy your Lovable, Cursor or Bolt app to EU servers in a weekend. Keep the vibe-coding workflow, lose the US-provider compliance mess.