

Zero-Config Kubernetes: Warum Einfachheit gewinnt
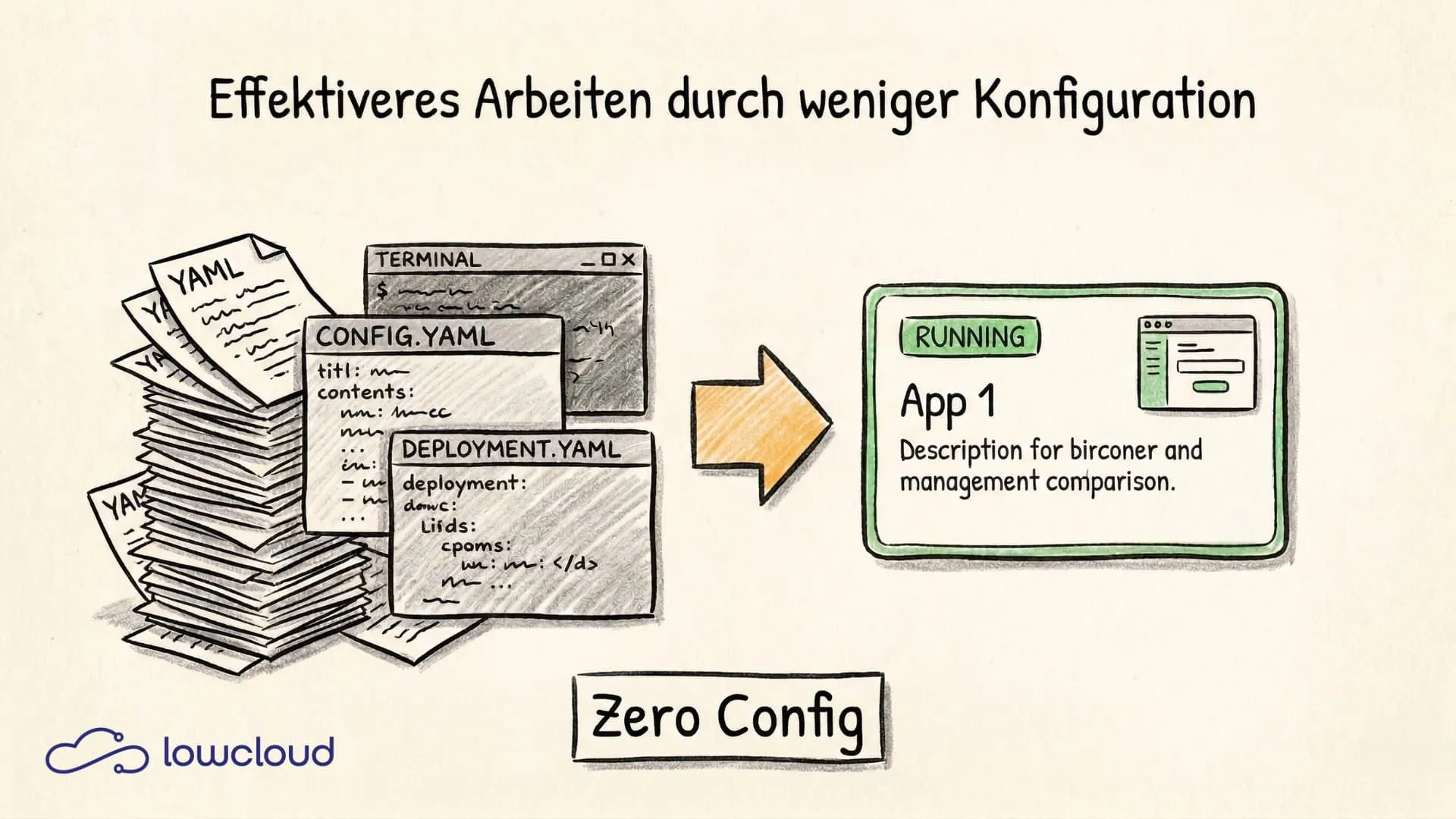
Kubernetes kann fast alles, aber dieser Satz hat einen Haken. Die Fähigkeit, fast alles zu können, bedeutet auch, dass man fast alles selbst konfigurieren muss. Für viele Teams ist das kein theoretisches Problem, sondern ein praktisches, das täglich Stunden kostet und Deployments verzögert. Zero-Configuration ist kein Verzicht auf Kontrolle, es ist eine Designentscheidung, die sagt: Sinnvolle Defaults sind besser als erzwungene Freiheit.
Was Zero-Configuration eigentlich bedeutet
Der Begriff stammt ursprünglich aus der Web-Entwicklung. Ruby on Rails hat ihn popularisiert, Maven hat ihn für Java-Builds übernommen, und Webpack hat ihn irgendwann wieder vergessen, was sich gerächt hat. Die Kernidee ist simpel: Ein System sollte ohne oder mit minimaler Konfiguration funktionieren, wenn man den häufigsten Anwendungsfall abdeckt.
Für Infrastruktur und Kubernetes bedeutet das: Eine Plattform, die weiß, wie ein typisches Deployment aussieht, sollte nicht verlangen, dass jedes Team dieses Wissen von Grund auf neu in YAML übersetzen muss. Netzwerkkonfiguration, Ressourcenlimits, Health Checks, TLS-Terminierung, das sind keine individuellen Entscheidungen für jedes Projekt. In 80 % der Fälle sind die Anforderungen identisch.
Zero-Configuration heißt nicht, dass man nichts konfigurieren kann. Es heißt, dass man es nicht muss, um anzufangen.
Wie viel Konfigurationsaufwand Kubernetes wirklich verursacht
Wer Kubernetes selbst aufgesetzt hat, kennt das Gefühl. Man fängt an, eine einfache Applikation zu deployen, und landet irgendwann bei einem Stapel YAML-Dateien: Deployment, Service, Ingress, ConfigMap, Secret, HorizontalPodAutoscaler, NetworkPolicy. Für eine App, die in drei Umgebungen laufen soll, multipliziert sich das schnell.
Das ist keine Kritik an Kubernetes als System. Es ist ein leistungsfähiges Werkzeug, das für komplexe, skalierbare Infrastruktur gebaut wurde. Aber dieses Werkzeug behandelt Konfiguration als explizite Verantwortung des Nutzers bei jedem Detail, in jeder Umgebung, für jedes Team.
Was dabei entsteht, ist kein böser Wille, sondern Konfigurationsdrift: Jedes Team entwickelt seine eigenen Konventionen, seine eigenen Templates, seine eigenen Workarounds. Nach zwei Jahren hat man nicht eine Kubernetes-Plattform, sondern zehn leicht verschiedene Kubernetes-Setups, die alle behaupten, dasselbe zu tun. Warum minimalistische Cloud-Architektur dieses Problem strukturell adressiert, beschreiben wir in einem eigenen Artikel.
Der eigentliche Aufwand liegt nicht nur im initialen Setup. Er liegt im laufenden Betrieb: neue Entwickler einarbeiten, Konfigurationen aktuell halten, Fehler debuggen, die aus inkonsistenten Setups entstehen.
Convention over Configuration. Ein altes Prinzip, das Cloud Native neu braucht
Das Prinzip ist älter als Kubernetes. Martin Fowler hat es beschrieben, Rails hat es bekannt gemacht: Ein Framework sollte Entscheidungen für den Entwickler treffen, solange diese Entscheidungen die häufigsten Anwendungsfälle korrekt abdecken. Der Entwickler muss nur dann eingreifen, wenn er vom Standardverhalten abweichen will.
In der Kubernetes-Welt hat sich dieses Denken schwer getan. Kubernetes ist bewusst als Plattform für Plattformen konzipiert, es bietet Primitives, keine Meinungen. Das macht Sinn auf der Ebene des Orchestrators selbst. Aber die Schicht darüber, die Entwickler täglich nutzen, hat lange gefehlt.
Was sich verändert hat: Plattformen wie Vercel, Railway oder Render haben gezeigt, dass Entwickler bereit sind, Kontrolle abzugeben, wenn die Defaults stimmen. Das Wachstum dieser Plattformen ist kein Zufall – es ist ein Signal.
Was gute Defaults auszeichnet
Nicht jeder Default ist ein guter Default. Schlechte Defaults sind solche, die beim Skalieren brechen, Sicherheitslücken öffnen oder so restriktiv sind, dass sie bei der ersten realen Anforderung geändert werden müssen.
Gute Defaults haben drei Eigenschaften:
Sicherheit: Der Default-Zustand sollte der sichere Zustand sein. Ein Pod ohne explizite SecurityContext-Einstellungen sollte nicht als Root laufen. TLS sollte standardmäßig aktiviert sein. Netzwerkzugriff sollte per Default eingeschränkt, nicht offen sein.
Funktionalität: Der Default muss funktionieren. Ein Health Check, der standardmäßig konfiguriert ist, aber auf einen nicht existierenden Endpoint zeigt, ist schlechter als gar kein Health Check.
Anpassbarkeit: Wenn jemand vom Default abweichen muss, sollte das möglich sein – ohne das gesamte Abstraktionsmodell zu verlassen. Zero-Configuration bedeutet einfaches Getting-Started, nicht ein Gefängnis.
Zero-Configuration Kubernetes in der Praxis
Managed Kubernetes-Dienste wie GKE, EKS oder AKS nehmen einen Teil der Last ab. Sie managen den Control Plane, updates, und Infrastruktur darunter. Aber die Applikationsebene, wie Deployments strukturiert sind, wie Networking funktioniert, wie Environments getrennt werden, bleibt Aufgabe des Teams.
PaaS-Layer auf Kubernetes gehen einen Schritt weiter. Sie abstrahieren die Kubernetes-Primitives hinter einer höheren Schnittstelle: Statt eines Deployments gibt es eine App. Statt eines Ingress-Objekts gibt es eine Domain. Statt eines HPA gibt es eine Skalierungsrichtlinie in lesbarer Form.
DevOps-as-a-Service-Plattformen gehen oft noch einen Schritt weiter: Sie liefern nicht nur die Abstraktion, sondern übernehmen zusätzlich Betrieb, Monitoring, Security-Baselines und Incident-Handling als Service, sodass Teams sich noch stärker auf die Produktentwicklung konzentrieren können. Und das ganze ohne Vendor Lock-In, wie es oftmals bei PaaS-Anwendungen der Fall ist.
Das Ergebnis: Ein Entwickler kann eine App deployen, ohne jemals eine YAML-Datei gesehen zu haben. Ein DevOps-Engineer kann Infrastrukturstandards zentral definieren, die alle Teams automatisch einhalten.
Wann Zero-Config an Grenzen stößt
Kein Ansatz passt für jeden Kontext. Zero-Configuration auf PaaS-und Ebene hat Grenzen, die man kennen sollte.
Sehr spezifische Infrastruktur: Wer GPU-Workloads, spezialisierte Netzwerkarchitekturen oder Bare-Metal-Anforderungen hat, wird mit opinionated Defaults schnell an Grenzen stoßen.
Compliance-getriebene Umgebungen: Regulatorische Anforderungen können sehr spezifische Konfigurationen verlangen, die ein generischer Default nicht abdeckt. Hier braucht man eine Plattform, die sowohl gute Defaults als auch feingranulare Anpassbarkeit bietet.
Migrationsszenarios: Wer eine komplexe, gewachsene Kubernetes-Infrastruktur hat, kann nicht von heute auf morgen auf Zero-Config umsteigen. Migration braucht eine klare Strategie.
Das sind reale Einschränkungen, aber sie betreffen einen deutlich kleineren Teil der Teams, als die Kubernetes-Community manchmal annimmt.
Developer Experience als Geschäftsentscheidung
Time-to-Deploy ist eine Metrik, die selten gemessen wird und die trotzdem fast alles über die Gesundheit eines Entwicklungsprozesses sagt. Wie lange dauert es, bis ein neuer Entwickler seinen ersten Pull Request in Produktion hat? Wie viele Stunden verbringt ein erfahrenes Team pro Woche damit, Infrastruktur zu konfigurieren statt Features zu bauen?
Diese Zahlen sind kein abstraktes DX-Thema. Sie sind direkte Produktivitätsverluste.
Konfigurationsaufwand ist besonders teuer, weil er nicht linear skaliert. Je mehr Projekte, Teams und Umgebungen ein Unternehmen hat, desto mehr Konfigurationsarbeit akkumuliert sich. Und weil Konfiguration selten dokumentiert wird, ist dieses Wissen oft personengebunden – ein Risiko, das sich beim nächsten Personalwechsel zeigt.
Die versteckten Kosten von Kubernetes-Komplexität
Der offensichtliche Kostenfaktor ist Personalaufwand: Jemand muss die Infrastruktur verstehen, aufbauen und warten. Aber es gibt subtilere Kosten.
Fehlerquellen durch Komplexität: Jede Konfigurationszeile ist eine potenzielle Fehlerquelle. Ein falsch gesetztes Ressourcenlimit, ein fehlender Network Policy Rule, ein falsch konfigurierter Liveness Probe. Diese Fehler sind schwer zu debuggen und teuer in der Produktion.
Onboarding-Aufwand: Ein neuer Entwickler, der drei Wochen braucht, um die Infrastruktur zu verstehen, bevor er produktiv wird, ist ein realer Kostenfaktor. Zero-Configuration-Plattformen reduzieren diesen Aufwand drastisch.
Kognitive Last: Entwickler, die gleichzeitig über Business-Logik und Kubernetes-Internals nachdenken müssen, machen schlechtere Entscheidungen in beiden Bereichen. Fokus ist eine begrenzte Ressource.
Zero-Configuration Kubernetes mit lowcloud
lowcloud setzt genau hier an. Als Kubernetes-DaaS-Plattform bringt lowcloud sinnvolle Defaults für Security, Networking, Skalierung und Monitoring mit – ohne dass Teams diese selbst definieren müssen. Wer tiefer eingreifen will, kann es. Wer einfach deployen will, kann das direkt tun.
Das Ziel ist nicht, Kubernetes zu verstecken. Es ist, die Kubernetes-Komplexität dort zu managen, wo sie anfällt – auf Plattformebene – statt sie auf jedes Entwicklungsteam zu verteilen.
Wenn dein Team mehr Zeit mit Produktentwicklung verbringen will und weniger mit Infrastrukturkonfiguration, ist das der Ausgangspunkt, über den es sich lohnt nachzudenken.
Bring Your Own Cloud: Was das Modell bedeutet und warum es Fahrt aufnimmt
BYOC ist kein weiterer Cloud-Flavour, sondern ein anderes Liefermodell: Der Anbieter deployt in deine Infrastruktur. Was das technisch bedeutet und für wen es relevant ist.
Minimalistische Cloud-Architektur: Weniger ist stabiler
Warum weniger Komponenten in der Cloud mehr Stabilität bringen – und wie Teams Kubernetes-Komplexität gezielt reduzieren können.