

Was ist Kubernetes? Container-Orchestrierung verständlich erklärt
Container haben die Art und Weise, wie wir Software entwickeln und ausliefern, grundlegend verändert. Doch sobald aus ein paar Containern Dutzende oder Hunderte werden, stößt die manuelle Verwaltung schnell an ihre Grenzen. Genau hier kommt Kubernetes ins Spiel – eine Plattform, die das Management containerisierter Anwendungen automatisiert und skalierbar macht. Doch was ist Kubernetes genau, wie funktioniert es, und wann macht der Einsatz wirklich Sinn?
Die Entstehung von Kubernetes
Kubernetes wurde ursprünglich von Google entwickelt und basiert auf über 15 Jahren Erfahrung mit internen Systemen wie Borg und Omega, die Millionen von Containern in Googles Rechenzentren orchestrieren. 2014 wurde Kubernetes als Open-Source-Projekt veröffentlicht und 2015 der Cloud Native Computing Foundation (CNCF) übergeben. Heute ist Kubernetes zum De-facto-Standard für Container-Orchestrierung geworden und wird von einer riesigen Community aus Entwicklern, Unternehmen und Cloud-Anbietern weiterentwickelt.
Der Name "Kubernetes" stammt aus dem Griechischen und bedeutet "Steuermann" oder "Pilot" – eine passende Metapher für eine Plattform, die Container durch komplexe Infrastrukturen navigiert. Das Projekt wird häufig als K8s abgekürzt (K, gefolgt von acht Buchstaben, gefolgt von s).
Das Problem, das Kubernetes löst
Vor der Verbreitung von Container-Orchestrierung war das Deployment von Anwendungen oft mühsam und fehleranfällig. Mit Docker wurden Container zwar populär, doch Docker allein reicht nicht aus, sobald Anwendungen auf mehreren Servern laufen müssen. Entwickler und DevOps-Teams stehen dann vor Herausforderungen wie:
- Verteilung von Containern über mehrere Server (Nodes)
- Load Balancing zwischen Container-Instanzen
- Automatisches Neustarten ausgefallener Container
- Skalierung bei steigender Last
- Rolling Updates ohne Ausfallzeiten
- Service Discovery und Netzwerk-Konfiguration
- Storage-Management für persistente Daten (z. B. PostgreSQL auf Kubernetes)
All diese Aufgaben manuell zu erledigen, ist nicht nur zeitaufwendig, sondern auch fehleranfällig. Kubernetes automatisiert diese Prozesse und bietet eine deklarative API, mit der Entwickler den gewünschten Zustand ihrer Anwendung beschreiben, während Kubernetes sich um die Umsetzung kümmert.
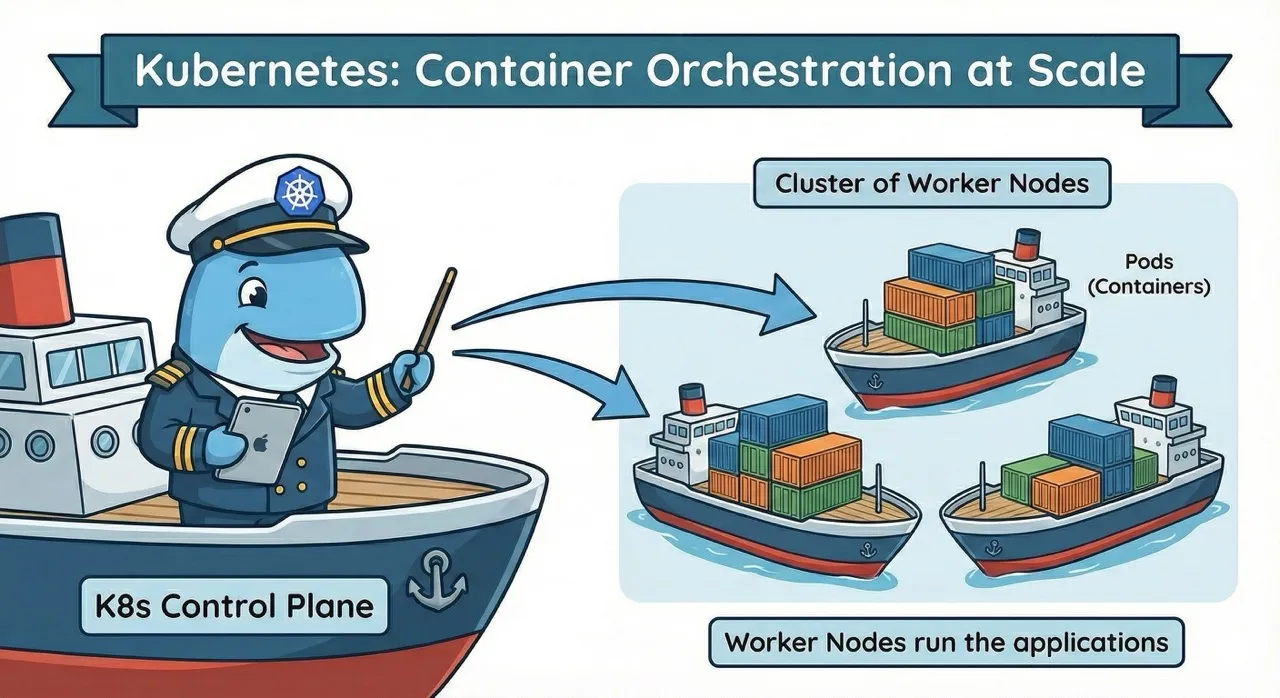
Wie funktioniert Kubernetes? Die Grundarchitektur
Kubernetes organisiert Ressourcen in Clustern, die aus mehreren Servern (physisch oder virtuell) bestehen. Ein Cluster besteht aus zwei Hauptkomponenten:
Control Plane: Das Gehirn des Clusters
Die Control Plane ist das Steuerungszentrum von Kubernetes und trifft alle Entscheidungen über den Cluster. Sie besteht aus mehreren Komponenten:
- API Server: Der zentrale Kommunikationspunkt, über den alle Anfragen laufen
- Scheduler: Entscheidet, auf welchem Node ein neuer Pod gestartet wird
- Controller Manager: Überwacht den Cluster-Zustand und gleicht ihn mit dem gewünschten Zustand ab
- etcd: Eine verteilte Key-Value-Datenbank, die den gesamten Cluster-Zustand speichert
Worker Nodes: Wo die Arbeit passiert
Die Worker Nodes sind die Server, auf denen die eigentlichen Container laufen. Jeder Node führt folgende Komponenten aus:
- Kubelet: Ein Agent, der mit der Control Plane kommuniziert und Container auf dem Node verwaltet
- Container Runtime: Die Software, die Container ausführt (z.B. containerd oder CRI-O)
- Kube-proxy: Verwaltet Netzwerk-Regeln und ermöglicht Kommunikation zwischen Pods
Das Desired State Prinzip
Das Herzstück von Kubernetes ist das Desired State Konzept. Anstatt imperative Befehle auszuführen ("Starte drei Container auf Server A"), beschreiben Nutzer den gewünschten Zustand ("Ich möchte, dass drei Instanzen meiner Anwendung laufen"). Kubernetes überwacht kontinuierlich den tatsächlichen Zustand (Actual State) und gleicht ihn automatisch mit dem gewünschten Zustand (Desired State) ab.
Fällt beispielsweise ein Container aus, erkennt Kubernetes die Abweichung und startet automatisch einen neuen Container, um den gewünschten Zustand wiederherzustellen – ganz ohne manuelles Eingreifen.
Die wichtigsten Kubernetes-Konzepte
Um Kubernetes effektiv zu nutzen, müssen Entwickler einige zentrale Konzepte verstehen:
Pods – die kleinste Einheit
Ein Pod ist die kleinste deploybare Einheit in Kubernetes. Ein Pod enthält einen oder mehrere Container, die sich Netzwerk und Storage teilen. In den meisten Fällen enthält ein Pod nur einen einzigen Container, aber es gibt Szenarien (z.B. Sidecar-Pattern), in denen mehrere Container eng zusammenarbeiten müssen.
Pods sind ephemeral, das heißt, sie können jederzeit gelöscht und neu erstellt werden. Kubernetes garantiert nicht, dass ein Pod auf demselben Node neu gestartet wird oder dieselbe IP-Adresse erhält.
Services – stabile Netzwerk-Endpunkte
Da Pods kurzlebig sind, braucht man eine stabile Möglichkeit, sie anzusprechen. Services bieten eine konstante IP-Adresse und DNS-Namen und leiten Traffic automatisch an die passenden Pods weiter. Services fungieren als Load Balancer und können verschiedene Arten haben:
- ClusterIP: Interner Zugriff innerhalb des Clusters
- NodePort: Zugriff von außen über Port auf jedem Node
- LoadBalancer: Integration mit Cloud-Load-Balancern
Deployments – deklaratives Management
Ein Deployment beschreibt, wie viele Replicas einer Anwendung laufen sollen und welches Container-Image verwendet wird. Deployments ermöglichen:
- Deklarative Updates: Änderung des gewünschten Zustands in einer YAML-Datei
- Rolling Updates: Schrittweises Ersetzen alter Pods durch neue
- Rollbacks: Zurückkehren zu einer vorherigen Version bei Problemen
Was kann Kubernetes? Die Kernfunktionen
Kubernetes bietet eine Vielzahl von Features, die das Management containerisierter Anwendungen vereinfachen:
Self-Healing und Ausfallsicherheit
Kubernetes überwacht kontinuierlich den Zustand aller Pods. Fällt ein Pod aus, wird automatisch ein neuer gestartet. Reagiert ein Pod nicht mehr auf Health Checks (Liveness und Readiness Probes), wird er neu gestartet oder aus dem Load Balancing entfernt. Das sorgt für hohe Verfügbarkeit ohne manuelle Intervention.
Automatische Skalierung
Mit dem Horizontal Pod Autoscaler kann Kubernetes automatisch die Anzahl der Pod-Replicas basierend auf CPU-Auslastung, Memory-Nutzung oder benutzerdefinierten Metriken anpassen. Bei steigender Last werden neue Pods hinzugefügt, bei sinkender Last werden sie wieder entfernt.
Der Vertical Pod Autoscaler passt die Ressourcen-Requests einzelner Pods an, während der Cluster Autoscaler bei Bedarf neue Nodes zum Cluster hinzufügt.
Rolling Updates und Rollbacks
Deployments ermöglichen Rolling Updates, bei denen neue Versionen schrittweise ausgerollt werden, während alte Versionen weiter laufen. Falls Probleme auftreten, können Änderungen mit einem einzigen Befehl rückgängig gemacht werden:
kubectl rollout undo deployment/my-app
Diese Strategie minimiert Ausfallzeiten und reduziert das Risiko fehlerhafter Deployments.
kubectl und YAML: Kubernetes in der Praxis
Die Interaktion mit Kubernetes erfolgt primär über kubectl, das Kommandozeilen-Tool für Kubernetes. Damit können Entwickler Ressourcen erstellen, anzeigen, ändern und löschen:
# Pods anzeigen
kubectl get pods
# Logs eines Pods anzeigen
kubectl logs my-pod
# Port-Forwarding für lokales Debugging
kubectl port-forward my-pod 8080:80
Die Konfiguration von Kubernetes-Ressourcen erfolgt typischerweise in YAML-Dateien, die den gewünschten Zustand beschreiben. Hier ein einfaches Beispiel für ein Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-app:1.0
ports:
- containerPort: 8080
Mit kubectl apply -f deployment.yaml wird diese Konfiguration im Cluster umgesetzt.
Wann lohnt sich Kubernetes?
Trotz aller Vorteile ist Kubernetes nicht für jedes Projekt die richtige Wahl. Die Plattform bringt Komplexität mit sich und erfordert Lernaufwand sowie operative Expertise.
Kubernetes macht Sinn, wenn:
- Sie mehrere Container-basierte Services orchestrieren müssen
- Hohe Verfügbarkeit und automatische Skalierung wichtig sind
- Sie Multi-Cloud- oder Hybrid-Cloud-Strategien verfolgen
- Ihr Team bereits Container-Erfahrung hat
- Sie eine standardisierte Plattform für verschiedene Anwendungen brauchen – auch für AI Agenten Infrastruktur in der Produktion
Kubernetes ist übertrieben, wenn:
- Sie nur eine einzelne, einfache Anwendung betreiben
- Ihr Team keine Ressourcen für Kubernetes-Expertise hat
- Docker Compose oder einfachere Orchestrierungs-Tools ausreichen — ein detaillierter Vergleich Kubernetes vs. Docker Swarm zeigt die Unterschiede
- Sie eine Serverless-Architektur bevorzugen
Eine ehrliche Einschätzung der eigenen Anforderungen und Ressourcen ist entscheidend. Nicht jedes Projekt braucht den Funktionsumfang von Kubernetes.
Kubernetes-Distributionen und Managed Services
Kubernetes ist ein Open-Source-Projekt, aber es gibt zahlreiche Distributionen und Managed Services, die den Einstieg und Betrieb erleichtern:
Für lokale Entwicklung:
- Minikube: Lightweight Kubernetes für Entwickler
- kind (Kubernetes in Docker): Schnelle lokale Cluster
- K3s: Leichtgewichtige Distribution für Edge, IoT und ressourcenschonende Cluster
Managed Kubernetes in der Cloud:
- Google Kubernetes Engine (GKE)
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- DigitalOcean Kubernetes
Enterprise-Distributionen:
- Red Hat OpenShift
- Rancher
- VMware Tanzu
Managed Services übernehmen die Verwaltung der Control Plane und reduzieren den operativen Aufwand erheblich. Teams können sich auf ihre Anwendungen konzentrieren, statt Cluster zu warten. Wer Kubernetes auf Hetzner-Infrastruktur ohne Betriebsaufwand nutzen will, findet in unserem Hetzner-Artikel eine konkrete Option.
Der Weg zum ersten Kubernetes-Cluster
Der Einstieg in Kubernetes muss nicht überwältigend sein. Ein pragmatischer Ansatz könnte so aussehen:
Schritt 1: Lokales Experimentieren
Installieren Sie Minikube oder kind und spielen Sie mit einfachen Deployments. Verstehen Sie Pods, Services und Deployments in einer sicheren lokalen Umgebung.
Schritt 2: Tutorials und Dokumentation
Die offizielle Kubernetes-Dokumentation bietet ausgezeichnete Tutorials. Arbeiten Sie diese durch und bauen Sie einfache Anwendungen nach.
Schritt 3: Managed Service nutzen
Für Production-Workloads empfiehlt sich ein Managed Kubernetes Service. Die Setup-Komplexität ist deutlich geringer, und Sie können sich auf das Deployment Ihrer Anwendungen konzentrieren.
Schritt 4: Monitoring und Logging
Implementieren Sie von Anfang an Monitoring mit Prometheus und Grafana und zentrales Logging (z.B. Loki-Stack oder EFK mit Fluent Bit). Observability ist in verteilten Systemen entscheidend.
Schritt 5: GitOps und CI/CD
Automatisieren Sie Deployments mit GitOps-Tools wie ArgoCD oder Flux und integrieren Sie Kubernetes in Ihre CI/CD-Pipeline.
Kubernetes als Basis für PaaS-Plattformen
Kubernetes ist leistungsfähig, aber auch komplex. Viele Unternehmen möchten von den Vorteilen der Container-Orchestrierung profitieren, ohne sich mit der operativen Komplexität von Kubernetes auseinandersetzen zu müssen. Genau hier setzen moderne Platform-as-a-Service (PaaS)-Lösungen an.
Diese Plattformen bauen auf Kubernetes auf und bieten eine abstrahierte Schicht, die Entwicklern ein Heroku-ähnliches Deployment-Erlebnis ermöglicht – mit git push zum Production-Deployment – während im Hintergrund die Robustheit und Skalierbarkeit von Kubernetes genutzt wird. Teams erhalten Self-Service-Zugang zu Ressourcen, ohne YAML-Dateien schreiben oder Cluster-Details verstehen zu müssen.
Solche Kubernetes-basierten PaaS-Lösungen kombinieren das Beste aus beiden Welten:
- Die Standardisierung und Portabilität von Kubernetes
- Die Developer Experience einer einfachen Deployment-Plattform
- Souveränität durch Betrieb auf eigener Infrastruktur
- Kosteneffizienz durch Multi-Tenancy und optimale Ressourcen-Nutzung
Für Teams, die Kubernetes-Vorteile ohne Kubernetes-Komplexität möchten, ist eine PaaS-Plattform oft der pragmatischste Weg. Wie Zero-Config-Ansätze Deployments vereinfachen, zeigt unser separater Artikel. Sie erhalten automatische Skalierung, Self-Healing und deklaratives Management – ohne ein dediziertes Kubernetes-Expertenteam aufbauen zu müssen.
Fazit
Kubernetes hat die Art und Weise, wie moderne Cloud-native Anwendungen betrieben werden, nachhaltig verändert. Die Plattform bietet umfangreiche Features für Orchestrierung, Skalierung und Self-Healing und ist zum Industriestandard geworden. Gleichzeitig sollte die Komplexität nicht unterschätzt werden – Kubernetes ist ein umfangreiches Werkzeug, das sorgfältige Planung und Know-how erfordert.
Für Teams mit komplexen, verteilten Anwendungen und entsprechenden Ressourcen ist Kubernetes eine ausgezeichnete Wahl. Wer die Kubernetes-Migration konkret angehen möchte, findet in unserem Migrationsleitfaden einen strukturierten Einstieg. Für kleinere Projekte oder Teams ohne dedizierte DevOps-Kapazitäten können einfachere Alternativen oder abstrahierte PaaS-Plattformen die bessere Option sein.
Die Frage ist nicht "Brauche ich Kubernetes?", sondern "Brauche ich die Vorteile von Container-Orchestrierung, und wenn ja, auf welcher Abstraktionsebene?". Die Antwort darauf bestimmt, ob Sie direkt mit Kubernetes arbeiten oder eine Plattform nutzen, die Kubernetes-Power mit Entwicklerfreundlichkeit verbindet.
Was ist Kustomize? Kubernetes-Configs sauber verwalten
Kustomize verwaltet Kubernetes-Konfigurationen über Bases und Overlays – ohne Templates. So bleiben YAML-Dateien lesbar, valide und flexibel anpassbar.
Die besten Heroku-Alternativen 2026
Heroku ist im Maintenance-Modus. Wir vergleichen Render, Railway, Fly.io, Porter und lowcloud als ernstzunehmende Alternativen für Teams.