

Citizen Developer: Schnell coden, sicher deployen
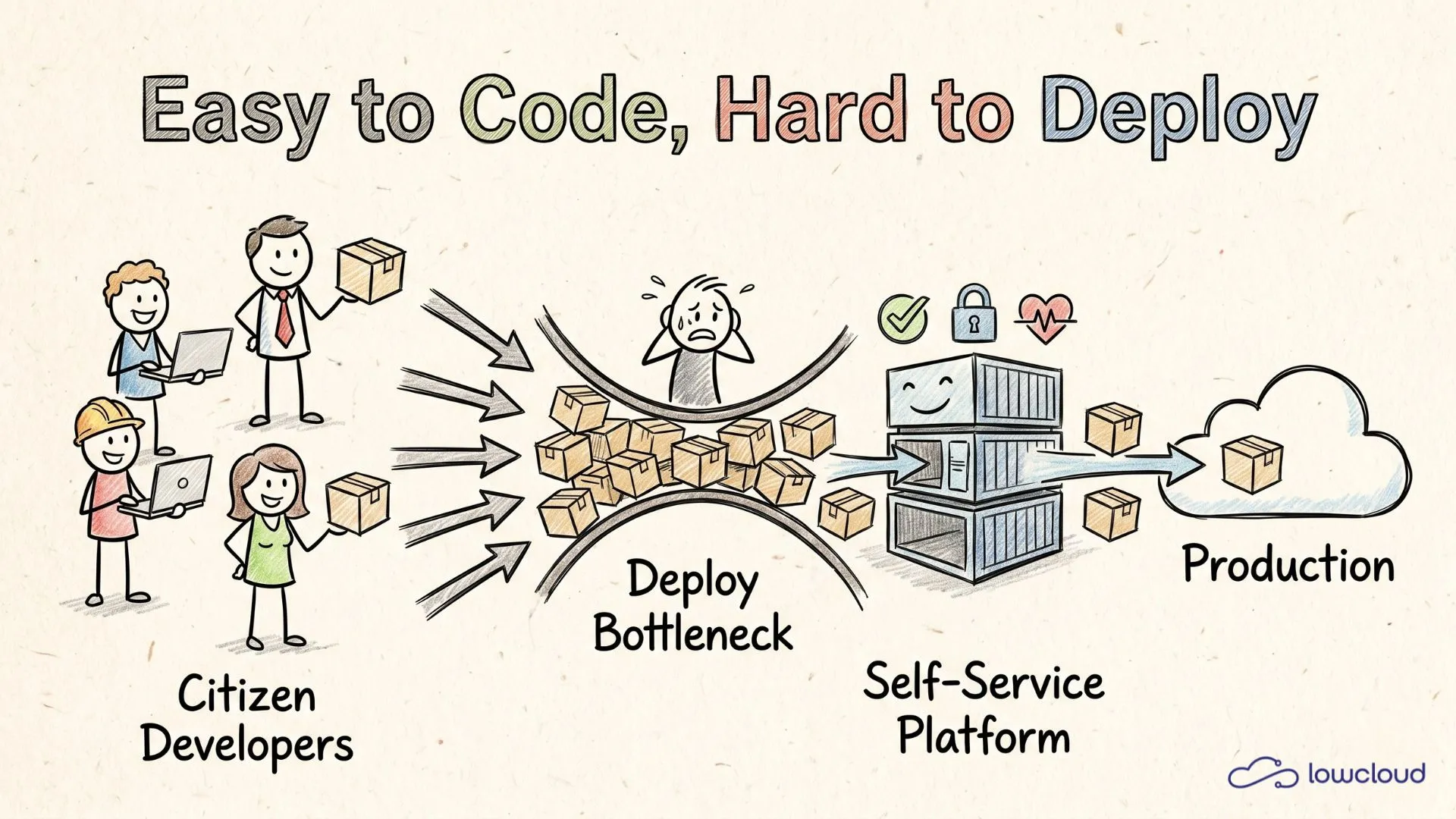
Vibe Coding senkt die Einstiegshürde fürs Programmieren so stark, dass plötzlich viel mehr Menschen im Unternehmen „Software bauen" können, zumindest bis zum Punkt, an dem der Code lokal läuft. Genau dort kippt die Realität: Sobald aus einem Prototyp ein Service wird, der zuverlässig laufen, überwacht, aktualisiert und abgesichert werden muss, wird Deployment und Betrieb zum Nadelöhr.
Dieser Artikel erklärt, warum das passiert, welche Risiken entstehen, und wie du mit Platform Engineering und Self-Service Deployment dafür sorgst, dass Citizen Developer und Produktteams produktiv bleiben, ohne dass euch Shadow IT und Compliance um die Ohren fliegen.
Was „Vibe Coding" eigentlich verändert (und was nicht)
Der Begriff Vibe Coding beschreibt nicht „magisches Programmieren ohne Denken", sondern eine neue Arbeitsweise: Menschen formulieren ein Ziel, lassen sich von LLMs Code vorschlagen, iterieren schnell und akzeptieren, dass nicht jede Zeile im Detail verstanden werden muss, solange das Ergebnis stimmt. Für bestimmte Klassen von Problemen funktioniert das erstaunlich gut:
- kleine interne Tools
- UI-lastige Prototypen
- Skripte und Automationen
- Glue-Code zwischen APIs
- Datenaufbereitung und Reporting
Was es nicht automatisch löst: Architekturentscheidungen, Sicherheitskonzepte, Lifecycle-Management, Releases, Datenhaltung, Observability. Genau das sind aber die Themen, die ab Tag 2 (Day 2 Operations) relevant werden.
Die wichtigste mentale Umstellung: Vibe Coding macht „eine Lösung bauen" leichter. Es macht „eine Lösung verantwortbar betreiben" nicht leichter – eher im Gegenteil, weil mehr Lösungen entstehen.
Warum plötzlich mehr Teams Software shippen
Wenn der Aufwand, von „Ich hab eine Idee" zu „Ich hab etwas, das funktioniert" drastisch sinkt, verändert sich das Verhalten in Organisationen. Statt Tickets an Engineering zu geben und Wochen zu warten, bauen Fachbereiche Dinge selbst:
- Sales baut ein Tool, das Leads aus mehreren Quellen zusammenführt.
- Finance automatisiert Reports und Freigabeprozesse.
- Operations bastelt ein Dashboard für Lieferketten-Status.
- Marketing nutzt Webhooks, um Kampagnen-Events zu synchronisieren.
- Data Teams bauen kleine Services, die Daten anreichern oder validieren.
Das ist nicht neu (Excel-Makros, Access-DBs, Zapier, Low-Code gab es immer). Neu ist, wie schnell daraus „echte Software" wird: Web-UIs, kleine APIs, Cronjobs, Container, die irgendwo laufen müssen.
Damit verschiebt sich auch die Rolle von Engineering: weniger als „Produzenten jeder einzelnen App", mehr als „Betreiber und Enabler", also Platform Engineering.
Der neue Bottleneck: Deployment & Betrieb
Im Notiz-Snippet auf der Seite steckt der Kern schon drin: „der bottleneck geht in richtung Deployment und Betrieb". Genau das ist die typische zweite Phase nach der Vibe-Coding-Euphorie, in der Deployment zum Engpass wird.
Warum Deployment schwerer ist als „Code generieren"
Ein LLM kann dir in Minuten ein kleines Backend schreiben. Aber damit es im Unternehmen nutzbar ist, brauchst du Antworten auf Fragen wie:
- Wo läuft das Ding? (Umgebung, Cluster, Region)
- Wie kommt es dahin? (CI/CD, Build, Deploy)
- Wie werden Secrets gehandhabt? (API Keys, DB-Passwörter)
- Wie sieht Observability aus? (Logs, Metriken, Alerts)
- Wer ist Owner? (On-call, Incident, Budget)
- Wie patchen wir Sicherheitslücken? (Base Images, Dependencies)
- Wie machen wir Rollbacks? (Versionierung, Releases)
- Wie gehen wir mit Daten um? (Backups, Migrationen, DSGVO)
Wenn diese Themen nicht standardisiert sind, wird jeder neue „kleine Service" zu einem Einzelstück. Das skaliert nicht.
Was in der Praxis zuerst bricht
Typische Deployment-Probleme von Vibe-Coding-Apps, wenn viele Teams anfangen, selbst zu shippen:
- Secrets landen im Code oder in Chat-Tools.
- „Ist doch nur intern" wird zur Standardausrede – bis es ein Incident ist.
- Kein Monitoring: Fehler werden erst entdeckt, wenn jemand schreit.
- Unklare Ownership: Niemand fühlt sich verantwortlich, wenn es nachts kaputtgeht.
- Kosten entgleisen: Hier ein VM-Experiment, dort ein Cloud-Service – niemand hat eine Gesamtsicht.
- Compliance-Lücken: Daten verlassen Regionen, Logs enthalten personenbezogene Daten, Zugriffe sind nicht auditierbar.
Das ist Shadow IT durch Vibe Coding in modern: nicht mehr nur SaaS-Tools, sondern selbstgebaute Deployments.
Risiken ohne Plattform: Shadow IT, Kosten, Compliance
Citizen Developer sind nicht das Problem. Das Problem ist, wenn ein Unternehmen Citizen Developer hat, aber keine Plattform und keine klaren Leitplanken.
Shadow IT: die Folge, nicht die Ursache
Shadow IT entsteht, wenn der „offizielle Weg" zu langsam oder zu teuer ist. Vibe Coding verstärkt das: Der Code ist schnell da, also wird auch ein „irgendwo deployen" gesucht – notfalls mit privaten Accounts, kostenlosen PaaS-Angeboten oder Copy-Paste-Anleitungen aus dem Netz.
Das Ergebnis ist eine Landschaft aus Services, die:
- niemand dokumentiert hat
- niemand patcht
- niemand überwacht
- niemand abschaltet
Compliance und Souveränität werden wieder „produktrelevant"
Gerade in Deutschland/Europa ist der Punkt nicht optional: Datenresidenz, Auftragsverarbeitung, Audit-Logs, Zugriffskontrolle. Wenn mehr Abteilungen coden, steigt die Wahrscheinlichkeit, dass jemand aus Versehen:
- personenbezogene Daten in nicht-konforme Tools schiebt
- Services in Regionen deployt, die nicht erlaubt sind
- keine Lösch- und Aufbewahrungsregeln einhält
Damit wird Souveränität ein praktisches Engineering-Thema, nicht nur ein Einkaufsthema.
Guardrails statt Gatekeeping: Wie du die Produktivität skalierst
Die produktive Antwort ist nicht „Verbot". Das funktioniert in der Realität nicht. Die produktive Antwort ist: Guardrails.
Guardrails sind technische und organisatorische Standards, die den Default sicher machen. Gute Guardrails reduzieren Entscheidungen pro Team und verhindern die häufigsten Fehler.
Bausteine, die sich bewährt haben
- Standardisierte Deploy-Targets: Container-Plattform, Jobs, Cron, ggf. Functions – aber klar definiert.
- Templates: Repo-Templates für typische App-Klassen (API, Worker, Frontend + Backend, Cronjob).
- CI/CD als Default: Ein Commit soll reproduzierbar bauen und deployen können.
- Approved Base Images: zentral gepflegt, regelmäßig gepatcht.
- Secret Management: kein Copy-Paste, sondern definierte Mechanismen.
- Observability by default: Logging, Metriken, Alerts – idealerweise automatisch.
- Policy-as-Code: Netzwerkregeln, Quotas, Freigaben für Datenbanken/Storage.
- Ownership & Lifecycle: Wer ist Owner? Wie wird deprovisioned? Was ist „abandoned"?
Ein simples Betriebsmodell für „viele kleine Apps"
Du brauchst kein Enterprise-Monster, um das zu starten. Ein minimaler Standard für viele kleine Apps reicht, wenn er konsequent ist. Beispiel:
- Jede App ist ein Container.
- Jede App hat ein Repo mit Template-Struktur.
- Jede App bekommt automatisch:
- ein Deployment (Staging/Prod)
- Logs
- Basis-Metriken
- Healthcheck
- Rollback via Versionspin
- Datenbanken werden als Managed Service bereitgestellt (inkl. Backups).
Damit wird „ich hab was gebaut" zu „ich kann es sicher laufen lassen".
Platform Engineering in einem Satz: Self-Service Deployment für Teams
Platform Engineering ohne Ops-Ticket ist im Kern: Engineering baut eine Plattform, die Teams erlaubt, Services schnell und sicher zu shippen – mit klaren Standards. Das ist genau die Gegenbewegung zum „jede App ist ein Schneeflocken-Deployment".
Wenn Vibe Coding mehr Output produziert, muss die Plattform den Durchsatz anheben. Sonst steht euer zentrales Team als Engpass im Weg:
- „Kannst du das deployen?"
- „Kannst du ein Secret setzen?"
- „Kannst du Monitoring einbauen?"
- „Kannst du eine DB provisionieren?"
Die Plattform sollte diese Fragen mit einem Self-Service-Workflow beantworten.
lowcloud als souveräne Deploy- und Betriebsbasis
Wenn ihr merkt, dass mehr Abteilungen Software shippen, braucht ihr vor allem eins: eine einheitliche, souveräne Grundlage für Deployment und Betrieb. Genau in dieser Lücke sitzen viele Teams: Sie können den Code schnell erzeugen, aber sie brauchen eine verlässliche Plattform, um ihn ohne großen Betriebsaufwand produktiv zu bekommen.
lowcloud ist hier als PaaS/Plattform interessant, weil es typische „Day-2"-Themen direkt adressiert:
- One Click Deployment für Container-basierte Services (weniger Handarbeit, weniger individuelle Setups)
- Container Deployment als Standard: gleiche Mechanik für viele App-Klassen
- Stateful Deployments inkl. Datenbanken, wenn die App nicht nur stateless ist
- Full-Stack Deployment: Frontend + Backend konsistent betreibbar
- Monitoring/Observability als fester Bestandteil, statt nachträglich angebaut
- Souveränität & Deutschland-Hosting: relevant für Compliance, Datenresidenz und auditierbare Betriebsprozesse
Wichtig ist: Eine Plattform ersetzt nicht gutes Engineering. Aber sie nimmt euch die repetitiven Teile ab und sorgt dafür, dass neue Services nicht jedes Mal bei Null anfangen, genau das, was ihr bei einer wachsenden Zahl an Citizen-Developer-Projekten braucht.
Shadow IT durch Vibe Coding: das neue Governance-Risiko
Vibe Coding erzeugt eine neue Form von Shadow IT: selbstgebaute Apps ohne Wartung, Security oder DSGVO. Warum Verbote scheitern und wie eine Plattform hilft.
Server, Docker, SSL: was du fürs App-Hosting brauchst
Server, Docker, SSL, Backups, Environment Variables: wir erklären die wichtigsten App-Hosting-Begriffe in Klartext, und welche du davon selbst können musst.