

Platform Engineering: einfacher deployen ohne Ops-Ticket
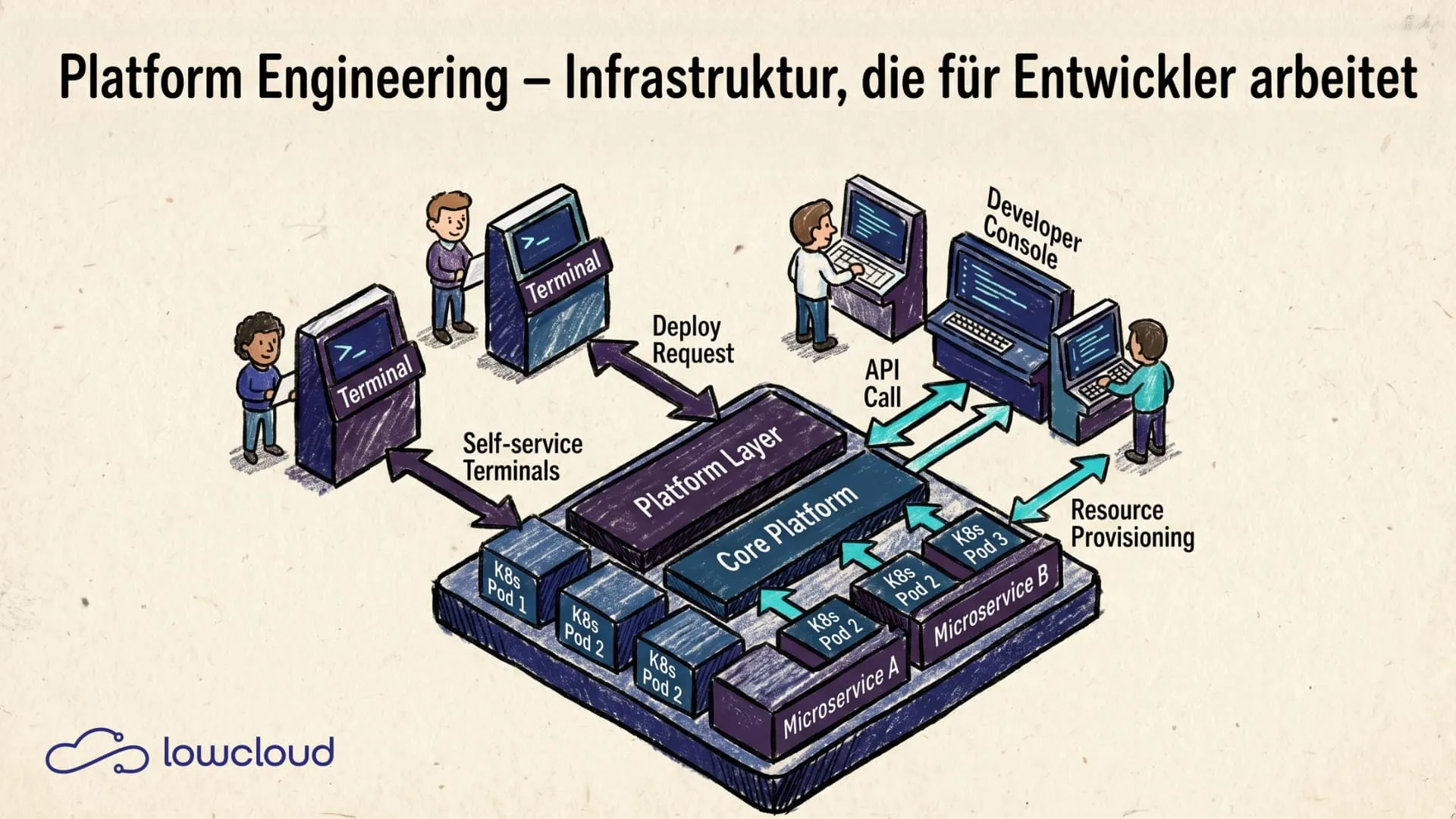
Entwicklungsteams verbringen zu viel Zeit damit, Infrastruktur zu konfigurieren statt Software zu bauen. Tickets an Ops-Teams, wochenlanges Warten auf Umgebungen, inkonsistente Deployment-Prozesse. Besonders sichtbar wird das, wenn Citizen Developer schnell Software shippen und der Betrieb zum Nadelöhr wird. Das ist kein Einzelproblem, sondern Alltag in vielen Unternehmen. Platform Engineering ist der Ansatz, der diesen Overhead systematisch abbaut: durch interne Plattformen, die Entwicklern das geben, was sie brauchen, ohne den Umweg über ein Ops-Ticket.
Was ist Platform Engineering?
Platform Engineering ist die Disziplin, die sich mit dem Aufbau und Betrieb interner Entwicklerplattformen beschäftigt. Das Ziel: Entwicklungsteams sollen produktiver arbeiten können, indem ihnen eine gut konzipierte, selbstbedienbare Infrastruktur zur Verfügung gestellt wird.
Der Begriff ist eng mit dem Konzept der Internal Developer Platform (IDP) verbunden, einer Plattformschicht, die häufig wiederkehrende Aufgaben wie das Bereitstellen von Umgebungen, das Konfigurieren von CI/CD-Pipelines oder das Deployen auf Kubernetes abstrahiert und automatisiert.
Platform Engineering ist dabei kein neues Tool und kein Framework, sondern eine organisatorische und technische Praxis. Es geht darum, wie Teams aufgestellt sind, welche Verantwortlichkeiten sie haben und welche Werkzeuge sie einsetzen, um Entwickler zu entlasten.
Die Internal Developer Platform
Die IDP ist das Herzstück von Platform Engineering. Sie ist keine fertige Software, die man kaufen kann, sondern ein System, das ein Platform Team aufbaut und betreibt, maßgeschneidert auf die Bedürfnisse der eigenen Entwickler.
Eine gut aufgebaute IDP bietet:
- Self-Service-Infrastruktur: Entwickler können Umgebungen, Datenbanken oder Deployments auf Abruf bereitstellen, ohne jemanden fragen zu müssen.
- Standardisierte Workflows: Wiederkehrende Schritte wie das Erstellen eines neuen Services oder das Aufsetzen einer Staging-Umgebung sind templatesiert und reproduzierbar.
- Abstraktion von Komplexität: Entwickler müssen keine Kubernetes-Manifeste schreiben oder Terraform-Module verstehen – die Plattform übernimmt die Details.
- Einheitliche Observability: Logging, Monitoring und Alerting sind von Anfang an eingebaut.
Der konkrete Aufbau variiert stark je nach Unternehmen. Manche setzen auf Backstage als Developer Portal, andere bauen ihre Plattform direkt auf GitOps-Tools wie ArgoCD auf. Entscheidend ist nicht das Tooling, sondern das Prinzip: Die Plattform bedient die Entwickler, nicht andersherum.
Der Golden Path
Ein Begriff, der in Platform-Engineering-Diskussionen immer wieder auftaucht, ist der Golden Path, manchmal auch Paved Road genannt. Gemeint ist ein vorgegebener, empfohlener Weg, wie ein Service aufgebaut, deployt und betrieben werden soll.
Der Golden Path ist kein Zwang. Entwickler können davon abweichen, wenn sie gute Gründe haben. Aber er macht den richtigen Weg zum einfachen Weg. Wenn das Template für einen neuen Microservice schon CI/CD, Monitoring und eine sinnvolle Kubernetes-Konfiguration mitbringt, wird kaum jemand von null anfangen wollen.
Das senkt die kognitive Last erheblich. Neue Teammitglieder sind schneller produktiv. Sicherheits- und Compliance-Anforderungen lassen sich einmal in den Pfad einbauen statt in jeden Service einzeln. Und Plattform-Updates können zentral eingespielt werden, ohne alle Teams manuell zu koordinieren.
Platform Engineering vs. DevOps vs. SRE
Die drei Begriffe werden oft durcheinandergebracht. Sie sind verwandt, aber nicht identisch.
DevOps ist eine Kultur und Praxis, die Entwicklung und Betrieb näher zusammenbringt. Es geht darum, Silos aufzubrechen und gemeinsame Verantwortung für Software über den gesamten Lebenszyklus hinweg zu schaffen. DevOps ist kein Team, sondern eine Denkweise.
Site Reliability Engineering (SRE) ist ein konkretes Implementierungsmodell, das Google entwickelt hat. SRE-Teams sind für die Zuverlässigkeit von Produktionssystemen verantwortlich. Sie arbeiten mit Error Budgets, SLOs und SLIs und greifen in Incident-Situationen ein.
Platform Engineering ist die logische Weiterentwicklung beider Ansätze. Während DevOps die Zusammenarbeit förderte und SRE die Zuverlässigkeit standardisierte, geht Platform Engineering einen Schritt weiter: Es baut die Infrastruktur, die Entwickler brauchen, damit sie DevOps überhaupt praktizieren können – ohne dass jedes Team das Rad neu erfinden muss.
In der Praxis gibt es Überschneidungen. Platform Teams lösen Reliability-Probleme strukturell, bevor sie entstehen. Und DevOps bleibt als kulturelles Fundament erhalten, auf dem Platform Engineering aufbaut.
Rollen und Aufgaben eines Platform Teams
Ein Platform Team ist kein klassisches Ops-Team. Es versteht sich als interner Dienstleister für Entwicklungsteams – mit dem Unterschied, dass es keine Tickets abarbeitet, sondern Systeme baut, die Tickets überflüssig machen.
Typische Aufgaben:
- Design und Weiterentwicklung der IDP
- Verwaltung der Kubernetes-Cluster und zugehöriger Infrastruktur
- Bereitstellung von Tooling für CI/CD, Secrets Management, Netzwerk und Observability
- Entwicklung und Pflege von Templates und Golden Paths
- Dokumentation und Enablement – das Platform Team muss erklären können, was es gebaut hat
Die wichtigste Eigenschaft eines Platform Teams ist Product Thinking. Die Entwickler sind die Kunden. Wenn die Plattform nicht benutzt wird oder als umständlich gilt, hat das Platform Team ein Problem – genau wie ein Produktteam, dessen Feature niemand nutzt.
Tools im Platform Engineering Stack
Es gibt keinen einheitlichen Stack. Die Tools werden je nach Anforderungen zusammengestellt. Einige verbreitete Komponenten:
- Backstage: Developer Portal von Spotify, das als Frontend für die IDP dienen kann. Bietet Service Catalogs, Templates und Dokumentation an einem Ort.
- Crossplane: Kubernetes-native Infrastructure-as-Code. Ermöglicht das Verwalten von Cloud-Ressourcen als Kubernetes-Objekte.
- ArgoCD / Flux: GitOps-Tools für Kubernetes-Deployments. Halten den Cluster-Zustand mit einem Git-Repository synchron.
- Terraform / OpenTofu: Klassisches Infrastructure-as-Code für Cloud-Ressourcen außerhalb von Kubernetes.
- Vault: Secrets Management. Sorgt dafür, dass Zugangsdaten nicht in Git landen.
- Prometheus + Grafana: Standard-Stack für Monitoring und Visualisierung.
Die Kunst liegt nicht darin, alle Tools zu kombinieren, sondern die richtige Auswahl zu treffen und sie so zu integrieren, dass sie für Entwickler einfach zu benutzen sind.
Kubernetes als Fundament
Die meisten modernen Internal Developer Platforms setzen auf Kubernetes als Orchestrierungsschicht. Das hat gute Gründe: Kubernetes bietet eine deklarative API, die sich gut für Self-Service eignet, ist cloud-agnostisch und hat ein breites Ökosystem.
Gleichzeitig ist Kubernetes komplex. Die Lernkurve ist steil, und die Konfiguration eines produktionsreifen Clusters ist nicht trivial. Das ist genau der Punkt, an dem Platform Engineering ansetzt: Das Platform Team verwaltet Kubernetes, damit Entwicklungsteams es nutzen können, ohne es vollständig verstehen zu müssen.
Ein Entwickler sollte in der Lage sein, einen Service zu deployen, ohne ein Kubernetes-Manifest zu schreiben. Die Plattform übersetzt eine einfache Konfiguration, etwa in YAML oder über ein Web-UI in die entsprechenden Kubernetes-Ressourcen.
Wie misst man Erfolg?
Platform Engineering ohne Metriken ist schwer zu rechtfertigen. Die wichtigsten Kennzahlen kommen aus zwei Bereichen:
DORA Metrics messen die Leistung von Entwicklungsteams:
- Deployment Frequency: Wie oft wird deployt?
- Lead Time for Changes: Wie lange dauert es von Commit bis Production?
- Change Failure Rate: Wie viele Deployments führen zu Vorfällen?
- Mean Time to Restore: Wie schnell werden Vorfälle behoben?
Eine gut aufgebaute Plattform verbessert alle vier Werte. Wenn Deployments einfacher und sicherer werden, passieren sie häufiger und mit weniger Fehlern.
Developer Experience (DevEx) ist schwerer zu messen, aber nicht weniger wichtig. Umfragen, Onboarding-Zeit neuer Entwickler und die Nutzungsrate von Plattformfeatures geben Aufschluss darüber, ob die Plattform wirklich hilft oder nur formal existiert.
Wie fängt man an?
Der häufigste Fehler beim Einstieg in Platform Engineering ist der Versuch, alles auf einmal zu bauen. Das ist der sicherste Weg, nach sechs Monaten ein System zu haben, das niemand benutzt.
Ein sinnvoller Einstieg:
- Schmerzpunkte identifizieren: Wo verlieren Entwickler am meisten Zeit? Welche Anfragen gehen am häufigsten an Ops-Teams?
- Klein anfangen: Einen einzigen Use Case automatisieren – zum Beispiel das Aufsetzen einer neuen Staging-Umgebung.
- Feedback einholen: Die Entwickler, für die man baut, sollten von Anfang an einbezogen werden.
- Iterieren: Die Plattform wächst mit den Anforderungen. Kein Big Bang.
Wer keine Zeit und Kapazität hat, eine vollständige interne Plattform von Grund auf aufzubauen, kann auch eine fertige PaaS nutzen, die viele der beschriebenen Konzepte bereits mitbringt, zum Beispiel lowcloud. Als Plattform liefert lowcloud einen Golden Path für Deployments, CI/CD und Infrastrukturmanagement, ohne dass ein eigenes Platform Team aufgebaut werden muss. Das ist kein Ersatz für Platform Engineering als Denkweise, aber ein pragmatischer Einstieg für Teams, die schnell vorankommen wollen.
App rechtssicher in der EU hosten: die Checkliste
So hostet ihr eure App rechtssicher in der EU: praktische Checkliste für Anbieterwahl, Verträge und Technik, nach Schrems II und CLOUD Act.
Vibe-Coded App deployen: schnell, günstig, in der EU
Push-to-Deploy für deine Lovable-, Cursor- oder Bolt-App auf EU-Servern an einem Wochenende. Workflow bleibt, das US-Provider-Compliance-Chaos verschwindet.