

Cut IT Costs with Automation: The Biggest Lever
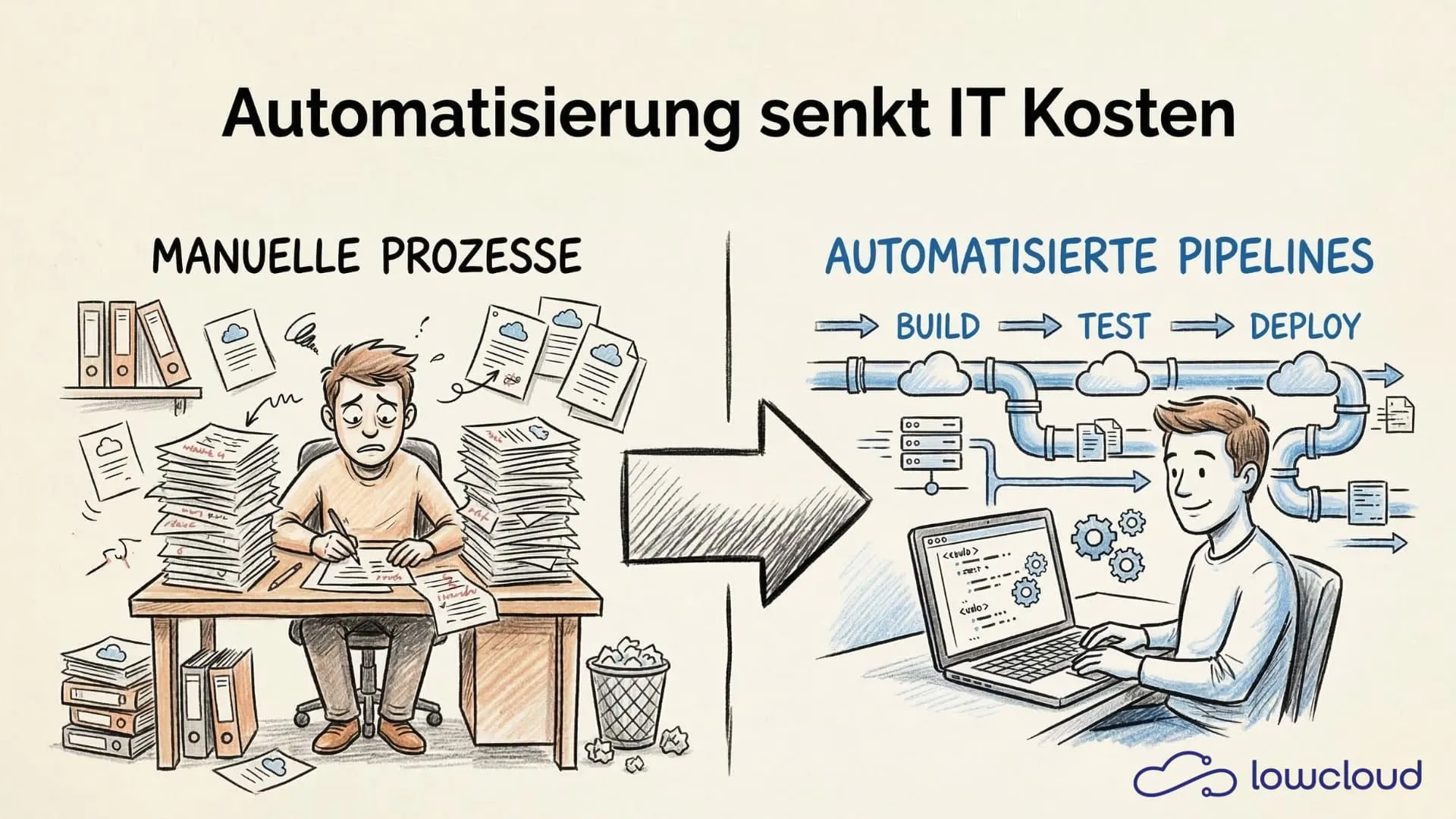
When companies want to cut IT costs, they usually think about cheaper cloud plans or headcount reduction first. Both miss the point. The biggest lever is automating manual operational tasks — and most teams have barely touched it.
Why Manual IT Is So Expensive
Look at how an average ops team spends its time: triggering deployments, adjusting configurations, renewing certificates, creating user accounts, maintaining monitoring rules, applying patches. None of these tasks are complex, but they all eat time. And time in IT is expensive.
The real problem isn't that these tasks need to be done. It's that they're done manually, over and over again. Each time with the risk of an error. Each time with the opportunity cost of someone not contributing to actual problem-solving.
On top of that: manual processes don't scale. A team managing ten services today can't simply manage a hundred services tomorrow with the same processes. More services mean more manual work — which means more headcount or more overtime. Both cost money.
Cutting IT Costs Through Automation: The Four Levers
Less Operational Overhead
The most obvious lever: tasks that take hours today take seconds after automation. An automated deployment process runs without anyone babysitting it. Automated onboarding creates user accounts without generating a ticket. An automated backup process runs overnight without supervision.
This doesn't necessarily mean positions get cut. In most teams, it means existing staff can finally do the work they were hired for: solving problems, improving architecture, enabling new features.
Fewer Incidents from Fewer Manual Errors
A major, often underestimated cost driver: incidents caused by human error. Miscopied configurations, forgotten rollbacks, overlooked dependencies during updates. These mistakes don't happen because of incompetence — they happen because manual processes are inherently error-prone.
Automated deployments via GitOps pipelines eliminate this source of failure. When a configuration change can only reach production through a versioned pull request, there's no "manual step" that can be forgotten or executed incorrectly. The change is traceable, testable, and instantly revertable if something goes wrong.
The cost of a single serious incident — downtime, customer communication, follow-up work — often exceeds months of investment in automation.
More Efficient Resource Usage (FinOps)
Cutting IT costs through automation also means: no more blanket over-provisioning of cloud resources. Without automation, teams size infrastructure for worst-case scenarios because nobody manually scales at 3 AM. The result: instances running at under 20% load 80% of the time — a problem we quantify in our cloud TCO analysis.
Automatic scaling changes this fundamentally. Kubernetes' Horizontal Pod Autoscaler (HPA) scales workloads up and down based on actual load. The Vertical Pod Autoscaler (VPA) automatically adjusts resource requests to match real consumption. For non-production environments, automatic shutdown schedulers can shut down clusters at night or on weekends.
These aren't theoretical savings. Teams regularly report 20–40% reduced cloud costs from consistent autoscaling and automated resource rightsizing alone.
Faster Time-to-Market
A less directly visible but very real cost factor: slow deployment cycles. When a feature release needs two weeks of lead time because of manual coordination, approvals, and deployment steps, that costs money. Developers wait, customers wait, feedback loops stretch out.
Automated CI/CD pipelines compress this process. Code goes into the branch, tests run automatically, on success it's deployed to staging, release happens with a click or fully automatically. What used to take days now takes hours.
Kubernetes as an Automation Platform
Kubernetes didn't become the standard for container infrastructure by accident. It comes with a complete automation layer designed for exactly the problems described above.
Operators automate complex stateful workloads: databases, message queues, monitoring stacks that previously required manual knowledge and regular intervention. Admission controllers and tools like OPA/Gatekeeper automatically enforce policies without someone having to review every deployment request. Self-healing through readiness and liveness probes ensures faulty pods are automatically restarted before a user even notices an error.
Platforms like lowcloud build on these Kubernetes primitives and make them team-ready — without every team having to build the mechanisms themselves.
Developer Self-Service: Relieving Ops Teams
An underestimated cost factor: the ticket overhead between development and operations. Every time a developer needs a new environment, wants to change a DNS entry, or needs a new database, a ticket lands with the ops team. The ops team prioritizes, processes, communicates back. Hours or days are lost.
Developer self-service platforms solve this problem structurally. Developers get the ability to request and manage standard resources themselves — within defined boundaries that the ops team has set up in advance. The ops team works once on the guardrails instead of a hundred times on individual tickets.
The result: developers move faster, ops teams can focus on more complex tasks, and the entire system scales without additional headcount.
Measuring Automation: Calculating ROI Concretely
Many teams shy away from investing in automation because the ROI seems hard to grasp. But the math is usually straightforward.
A practical framework:
- Time tracking: How many hours per week does the team spend on a specific manual task?
- Cost rate: What's the average hourly rate (internal or with overhead)?
- Implementation effort: How long does automating this task take as a one-time investment?
- Break-even: When does the investment pay for itself?
Example: A team spends 4 hours per week on manual deployment steps. At an internal cost rate of €80/h, that's €320 per week or nearly €17,000 per year. An automation effort costing two weeks of development time pays for itself in less than a month.
Add to that the harder-to-measure but very real factors: reduced incident costs, better developer satisfaction, lower error rates.
Where to Start: Practical Priorities
Not everything can be automated at once — and it doesn't need to be. The sensible order:
1. Deployment processes: The biggest lever for most teams. CI/CD pipelines can be introduced incrementally and pay off immediately.
2. Infrastructure provisioning: Terraform or Pulumi for reproducible infrastructure. No more manual clicks in the cloud console.
3. Scaling: Set up HPA and VPA in Kubernetes. Clear FinOps effect, low initial effort.
4. Monitoring and alerting: Automated alerts based on defined SLOs instead of manual dashboard monitoring.
5. Self-service: Developer portals and automated onboarding once the fundamentals are stable.
The most important principle: automation isn't a project with a beginning and an end. It's a continuous practice. Teams that regularly identify and automate a manual task build a significant advantage over months — in costs, reliability, and speed.
If you're looking for a platform that brings these automation mechanisms out-of-the-box — from Kubernetes-native autoscaling to GitOps deployments to developer self-service — lowcloud is built for that. The platform handles the infrastructure layer so your team can focus on what actually creates value.
Cloud Act vs. GDPR: The Risk for EU Businesses
US cloud services force European companies into a legal conflict. Why compliance measures fall short and what infrastructure decisions actually help.
NIS2 Compliance for DevOps Teams: What You Need to Do
NIS2 sets concrete technical requirements for DevOps teams. Learn what the directive demands and why legacy data centers are under pressure.